Part I
Foundations and Communication
Understanding what GenAI is, how it works, and how humans interact with it
Chapter 1: Foundations of Generative AI
Generative Artificial Intelligence (GenAI) represents a paradigm shift in how machines can create and innovate. This chapter lays the groundwork by defining GenAI, tracing its historical development, explaining its operational principles, and introducing the diverse array of models that power its capabilities.
1.1 What is Generative AI and its History
Generative AI refers to artificial intelligence systems capable of creating novel content—such as text, images, audio, or video, by learning patterns from existing data. While the concept has roots in early AI research, its recent prominence, particularly since 2022-2023, marks a significant leap forward in AI's creative potential.
The journey of Generative AI spans decades. Early explorations include chatbots like ELIZA in the 1960s, which simulated conversation. The development of neural networks through the 1980s and 1990s laid crucial groundwork, followed by the rise of deep learning in the 2000s. Key breakthroughs accelerated the field: Generative Adversarial Networks (GANs) were introduced by Ian Goodfellow and his colleagues in 2014, revolutionizing image generation. Diffusion models, which gradually refine noise into coherent data, began to emerge conceptually around 2015 and gained significant traction later. The release of OpenAI's GPT-3 (Generative Pre-trained Transformer 3) in 2020, and subsequently GPT-3.5 (powering early versions of ChatGPT) in late 2022, demonstrated unprecedented language capabilities. This led to an explosion of diverse GenAI models and applications starting in 2023, a period noted by McKinsey as one of rapid expansion and adoption (McKinsey, 2025, p. 16, Exhibit 8).
A common question is why generative AI is surging now. Its recent emergence is fundamentally driven by a convergence of three critical factors:
- Sophisticated AI Model Architectures: Innovations like the Transformer architecture have enabled models to understand and generate complex patterns with greater accuracy.
- Vast Datasets: The digital age has produced an unprecedented amount of data (text, images, code), crucial for training these large models. Notably, IDC estimates that 90% of a company's data is unstructured (Shelf & ViB, 2025, p. 7), highlighting the rich, albeit challenging, resource available for GenAI.
- Exponential Increase in Computing Power: Advances in GPUs and distributed computing have made it feasible to train models with billions or even trillions of parameters.
Generative AI's applications are diverse and rapidly expanding. According to McKinsey's 2025 "The State of AI" report, organizations are most commonly using GenAI to create text outputs (63% of respondents), followed by images (36%) and computer code (27%) (McKinsey, 2025). Broadly, applications span:
- Text Generation: Large language models create contextually relevant text for dialogue (chatbots), explanation, summarization, content creation, and translation.
- Image Generation: Techniques like GANs and Diffusion models produce high-quality, realistic, or artistic images used in art, design, advertising, and entertainment.
- Audio Generation: Creating music, synthesizing voices for text-to-speech applications, generating sound effects, finding use in media, entertainment, and education.
- Video Generation: Translating text descriptions or images into dynamic videos for fields like art, entertainment, education, marketing, and healthcare.
- Code Generation: Assisting software development by producing code snippets, functions, or even entire programs, aiding in debugging, testing, and rapid prototyping.
- Data Generation and Augmentation: Creating synthetic data to train other AI models where real-world data is scarce or private (e.g., in healthcare), or augmenting existing datasets to improve model robustness. This is particularly relevant for gaming, autonomous driving, and more.
- Virtual World Creation: Generating realistic environments, characters, and assets for gaming, simulations, entertainment, education, and metaverse platforms.
1.2 How Does Generative AI Work?
Understanding the mechanics of generative AI can be simplified through analogy. Consider training a dog: the task might be teaching it to press a button upon hearing a specific command. This process involves:
- Data Collection: The command (input) and the desired button press (output).
- Training Process: Repeated commands, with rewards (e.g., treats) for correct actions.
- Learning: The dog associates the command with the action, learning to ignore irrelevant factors (e.g., tone of voice, background noise, if not part of the signal).
- Iterative Improvement: The dog gets better with practice, perhaps with added distractions to test robustness.
- Testing and Deployment: Testing in new situations leads to reliable deployment (the dog pressing the button consistently on command).
Large language models (LLMs), a cornerstone of generative AI, operate through a more complex but conceptually similar process involving sophisticated architecture, extensive training, and inference (generation).
- Architecture: Based primarily on the Transformer architecture, LLMs utilize self-attention mechanisms across multiple layers, often containing billions of parameters (weights and biases that the model learns).
- Pre-training: LLMs undergo extensive pre-training on vast datasets, which can include internet text, books, articles, and code. They learn linguistic patterns, facts, reasoning abilities, and common sense knowledge through unsupervised learning—typically by predicting the next word (or token) in a sequence.
- Tokenization: Text is processed via tokenization, breaking it into manageable units like words or subwords.
- Contextual Understanding: Attention mechanisms are crucial, allowing the model to weigh the importance of different parts of the input text when making predictions, enabling it to understand context even over long sequences.
- Fine-tuning: After pre-training, models can be fine-tuned on smaller, more specific datasets to adapt them for particular tasks (e.g., medical text summarization, customer service responses) or to align them with desired behaviors (e.g., helpfulness, harmlessness).
- Inference: When given a prompt (input text), the model generates output text by repeatedly predicting the most likely next token, building up the response one token at a time.
- Zero-shot and Few-shot Learning: A remarkable capability of LLMs is their ability to perform tasks they weren't explicitly trained for (zero-shot) or with very few examples (few-shot), thanks to the general patterns learned during pre-training.
- Scaling Laws: The overall performance generally improves with scaling—increasing model size (number of parameters), dataset size, and the amount of computational resources used for training. Empirical studies, such as "Scaling Laws for Neural Language Models" by Kaplan et al. (2020, arXiv:2001.08361), demonstrate that performance scales predictably with increases in these factors, highlighting the importance of scaling them in tandem for optimal results.
The foundation of GenAI's recent success rests firmly on these three pillars: the evolution of sophisticated Models, the availability of massive amounts of Data (much of it unstructured), and the dramatic increase in Computing power. The SAS Generative AI Global Research Report emphasizes that while organizations expect GenAI successes, they often encounter stumbling blocks in implementation related to these areas, particularly in "increasing trust in data usage," "unlocking value," and "orchestrating GenAI into existing systems" (SAS, 2024). The quality and management of data, especially unstructured data which forms the bulk of enterprise information, is paramount. As the Shelf & ViB (2025, p. 7) report highlights, "Data quality is crucial for delivering trusted GenAl answers because ultimately the data becomes the answer."
1.3 Types of Generative AI Models
Generative AI encompasses a variety of models and techniques, each with unique strengths and applications. Key examples include Generative Adversarial Networks (GANs), Diffusion models, Transformers, Variational Autoencoders (VAEs), Retrieval-Augmented Generation (RAG), Recurrent Neural Networks (RNNs), Autoregressive Models, and Convolutional Neural Networks (CNNs), among others.
Large Language Models (LLMs), such as those powering ChatGPT (Chat Generative Pretrained Transformer), are predominantly based on the Transformer architecture. Developed by OpenAI, ChatGPT's primary purpose is generating human-like text responses conversationally. This is achieved by processing vast amounts of text data via unsupervised learning to grasp language patterns, grammar, facts, and even some reasoning capabilities. Modern GenAI, however, extends beyond text; multimodal models can process and generate content integrating multiple data types like images, audio, and text. Image generation, for instance, often involves models (like Diffusion models) learning to reverse a process of systematically adding noise to an image, enabling them to construct clear images from random noise during the generation phase.
Understanding specific model types can be aided by analogies:
- Generative Adversarial Networks (GANs): The Art Forgery Analogy. GANs feature a competitive dynamic between two neural networks: a Generator ("The Forger") that creates fake data (e.g., images) and a Discriminator ("The Detective") that tries to distinguish the fake data from real data. This adversarial process, where both networks improve over time, pushes the Generator to produce highly realistic outputs that are often indistinguishable from authentic data. (More details can be found at O'Reilly: https://www.oreilly.com/content/generative-adversarial-networks-for-beginners/)
- Diffusion Models: The Dust Cloud Analogy. These models learn by first taking clean data and gradually adding noise (like dust obscuring a picture) until it's essentially random. They then train a neural network to reverse this process, step-by-step. To generate new data, they start with pure noise and progressively "de-noise" it, guided by the learned reversal process, into a coherent and high-quality output. This allows for precise control over the generation process. (LeewayHertz provides an overview: https://www.leewayhertz.com/diffusion-models/)
- Transformer Models: The Orchestra Analogy. Fundamental to LLMs like GPT, Transformers use an "attention mechanism" (like an "Orchestra Conductor") to weigh the importance of different parts of the input sequence (the "musicians" or words) when generating an output. This allows the model to understand long-range dependencies and context within the text. "Multi-head attention" is like having multiple conductors, each focusing on different aspects of the "music" (text), leading to a richer and more nuanced understanding. (NVIDIA explains Transformers: https://blogs.nvidia.com/blog/what-is-a-transformer-model/)
- Variational Autoencoders (VAEs): The Compression/Decompression Analogy. VAEs consist of an encoder that compresses input data into a lower-dimensional, continuous latent space (a compact representation) and a decoder that reconstructs the original data from this latent representation. The "variational" aspect introduces a probabilistic approach to the encoding, ensuring the latent space has good properties that allow for generating new, similar data points by sampling from this space. They are useful for both data compression and creative generation. (IBM discusses VAEs: https://www.ibm.com/think/topics/variational-autoencoder)
- Retrieval-Augmented Generation (RAG): The Librarian and Author Analogy. RAG models enhance the generation capabilities of LLMs by first retrieving relevant information from an external knowledge base (the "Librarian" finding the right books or documents) based on the user's prompt. This retrieved information is then provided as context to the LLM (the "Author"), which uses it to generate a more accurate, up-to-date, and contextually grounded response. This is particularly useful for mitigating hallucinations and incorporating domain-specific or recent information. The Shelf & ViB report (2025, p. 7) notes RAG as a key strategy for leveraging an organization's (often unstructured) data. (AWS explains RAG: https://aws.amazon.com/what-is/retrieval-augmented-generation/)
The development of GenAI is extraordinarily rapid, with models constantly evolving in capability and efficiency. Performance benchmarks from platforms like the Chatbot Arena (https://chat.lmsys.org/?arena), which uses Elo ratings based on human preferences, offer valuable insights into the comparative strengths of leading models (e.g., OpenAI's GPT 5, Anthropic's Claude Sonnet 4.0 & Opus 4.1, Google's Gemini 2.5, Mistral AI's models) across various tasks. This dynamic landscape reflects a diversifying ecosystem with both large, proprietary models and increasingly powerful open-source alternatives. The SAS report (2024, p. 24) aptly notes, "LLMs alone do not solve business problems. GenAI is nothing more than a feature that can augment your existing processes, but you need tools that enable their integration, governance and orchestration."
Chapter 2: Business Integration of Generative AI
The integration of Generative AI into business operations is no longer a futuristic concept but a present-day imperative for organizations seeking to innovate, enhance efficiency, and gain a competitive edge. This chapter explores the strategic levels at which GenAI can be adopted, examines its transformative impact on business models and value creation, and works on the critical challenges and considerations organizations must navigate for successful implementation.
2.1 Four Levels of Integration
Integrating Generative AI into business operations can be approached at different strategic levels, each presenting unique complexities, costs, and potential for competitive advantage. Drawing from strategies observed in practice and insights from research (e.g., Scott Cook, Andrei Hagiu, and Julian Wright in Harvard Business Review, January-February 2024, "Manage Generative AI by Strategizing at Four Levels"), four key levels emerge:
Level 1: Adopt Publicly Available Tools. This entry-level approach involves using standard, off-the-shelf GenAI tools like public chatbots (e.g., GPT 5, Claude Sonnet 4.0), image generators (e.g., Midjourney, Gemini nano banana), video editors (e.g., Gemini Veo), or coding assistants. The primary aim is often to improve internal process efficiency, such as drafting emails, summarizing documents, or generating initial creative ideas.
- Complexity & Cost: Low. Easy to implement with minimal upfront investment.
- Customization: None for the underlying AI models themselves.
- Competitive Advantage: Often temporary, as these tools quickly become widely adopted and can be considered "table stakes."
- Considerations: Relying on third-party tools can raise data privacy and security concerns, especially if sensitive company information is inputted. The SAS report (2024, p. 6, 9) highlights that 76% of organizations are concerned about data privacy and 75% about security with GenAI.
Level 2: Customize Existing Tools. Organizations at this level tailor readily available AI tools to their specific needs. This typically involves leveraging APIs provided by model developers (e.g., OpenAI API, Anthropic API) or fine-tuning pre-trained models with proprietary company data and know-how. This allows for the creation of customized AI solutions that can enhance customer experiences (e.g., personalized support bots), add unique capabilities to products (e.g., AI-powered features), and potentially improve user interfaces through personalization.
- Complexity & Cost: Moderate. Requires technical expertise for API integration and fine-tuning, along with data preparation efforts.
- Customization: High for application, moderate for the core model (fine-tuning adapts an existing model).
- Competitive Advantage: Can be significant if the customization leverages unique data or addresses specific customer needs effectively.
- Considerations: Data governance for fine-tuning data is crucial. The Shelf & ViB report (2025, p. 11) notes that 57% of companies are "fine-tuning on your data" to address unstructured data issues, indicating this is a common approach.
Level 3: Create Automatic Data Feedback Loops. A more advanced strategy involves designing systems where the outputs and user interactions generated by AI tools automatically feed back into the system, continuously refining the model, associated processes, or knowledge bases with minimal human intervention. This requires redesigning products or services to deeply integrate AI and to capture reliable signals from customer usage that drive ongoing improvement. Such feedback loops can establish a compounding competitive advantage that is difficult for others to replicate, as the AI system becomes increasingly "smarter" and more attuned to the specific domain through usage.
- Complexity & Cost: High. Requires significant engineering effort, data infrastructure, and a strategic approach to product design.
- Customization: Very high, focusing on the entire ecosystem around the AI.
- Competitive Advantage: Potentially very strong and sustainable, creating a "data moat."
- Considerations: Ethical implications of data collection and algorithmic bias need careful management. Continuous monitoring is essential.
Level 4: Develop Proprietary Models. The most sophisticated and resource-intensive level entails building unique generative AI models from the ground up (foundation models) or significantly modifying existing open-source architectures, tailored specifically to address core business problems using internal data and expertise. This approach might be pursued by companies with unique data advantages or specific needs that off-the-shelf or fine-tuned models cannot meet.
- Complexity & Cost: Extremely high. Demands significant AI research talent, massive computational resources, and extensive datasets.
- Customization: Maximum flexibility and control over the model architecture and training process.
- Competitive Advantage: Can be substantial and highly sustainable if the model provides a breakthrough capability or solves a unique, high-value problem.
- Considerations: Very few companies have the resources for this. Success is not guaranteed, and it involves long development cycles. The McKinsey report (2025, p. 8, Singla commentary) advises organizations to "think big" and aim for "wholesale transformative change," which could align with this level for some.
As McKinsey's 2025 report observes, organizations are still in the "early days" but are actively "redesigning workflows, elevating governance, and mitigating more risks" as they move through these levels (McKinsey, 2025, p. 2).
2.2 Business Models and Value Creation
Generative AI holds immense potential to reshape business models and unlock new avenues for value creation across industries and functions. Its impact is increasingly evident in workplace trends, productivity metrics, and strategic organizational shifts. The McKinsey (2025, p. 2) report title itself, "The state of AI: How organizations are rewiring to capture value," underscores this focus.
Perceived Potential and Adoption Trends: The adoption of AI, including GenAI, is rapidly increasing. McKinsey (2025, p. 15) found that 78% of survey respondents reported their organizations use AI in at least one business function in July 2024, up from 72% in early 2024 and 55% a year prior. Specifically for GenAI, 71% of respondents stated their organizations regularly use it in at least one business function, a jump from 65% in early 2024 (McKinsey, 2025, p. 17). This rapid uptake signals a broad recognition of GenAI's potential. The SAS report (2024, p. 27) similarly notes that over half (54%) of businesses have begun to implement GenAI, with 86% investing in it in 2024 or planning for 2025.
Enterprises are committing significant resources to GenAI across various functions. The Shelf & ViB (2025, p. 3, 6) survey found the highest levels of GenAI commitment (planning, PoC, deployed, or scaling) in software development (87%), data management/BI/analytics (86%), and operations/process automation (83%).
Productivity and Output Quality Gains: Concrete evidence supports GenAI's ability to boost productivity and output quality. Studies have shown significant improvements:
- Software engineers coding up to twice as fast using AI assistance (Peng et al., 2023, "The Impact of AI on Developer Productivity: Evidence from GitHub Copilot").
- Consultants completing tasks 25% faster with 40% higher quality output when using GenAI tools (Dell'Acqua et al., 2023, "Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of AI on Knowledge Worker Productivity and Quality").
- Writing tasks being finished up to twice as quickly (Noy and Zhang, 2023, "Experimental Evidence on the Productivity Effects of Generative Artificial Intelligence").
Beyond speed and quality, benefits often extend to enhanced creativity and job satisfaction. The SAS report (2024, p. 4) found that among organizations embracing GenAI, 89% reported improved employee experience and satisfaction, 82% noted savings on operational costs, and 82% stated higher customer retention. The primary outcome targeted by companies for GenAI, according to Shelf & ViB (2025, p. 3, 7), is improving operational efficiency (61% of respondents).
Revenue and Cost Impacts: Organizations are beginning to see tangible financial benefits. McKinsey's latest survey (2025, p. 22-23) indicates an increasing share of respondents reporting value creation, with larger shares than in early 2024 stating their GenAI use cases have increased revenue and led to cost reductions within deploying business units. For instance, in the second half of 2024, 70% of those using GenAI in strategy and corporate finance reported revenue increases, and 61% using it in supply chain and inventory management reported cost decreases.
Accelerated Employee Development: Research by Brynjolfsson, Li, and Raymond (2023, NBER WP 31161, "Generative AI and Firm-Level Productivity Growth") demonstrated that AI assistance significantly helped newer customer support agents improve their performance, effectively reducing the learning curve and boosting resolutions per hour by up to 14%. This suggests GenAI can democratize expertise and accelerate onboarding.
Strategic Rewiring for Value Capture: To fully harness GenAI, organizations are undertaking significant changes. McKinsey (2025, p. 2) highlights that companies are "redesigning workflows, elevating governance, and mitigating more risks." Indeed, 21% of respondents using GenAI reported their organizations have fundamentally redesigned at least some workflows (McKinsey, 2025, p. 4). This often requires top-down C-suite commitment and leadership, as emphasized by Alexander Sukharevsky: "Effective AI implementation starts with a fully committed C-suite and, ideally, an engaged board" (McKinsey, 2025, p. 4).
2.3 Challenges and Considerations in GenAI Integration
While the potential of GenAI is vast, its successful integration is fraught with challenges that organizations must proactively address. These span data quality, governance, strategic alignment, technological hurdles, and talent acquisition.
1. Data Quality and Unstructured Data Management: The adage "garbage in, garbage out" is acutely relevant for GenAI. The quality of the data used to train and prompt these models directly determines the quality and reliability of their outputs.
- Scale and Impact of Unstructured Data Issues: The Shelf & ViB (2025) survey reveals the magnitude of this challenge: 85% of organizations manage over 1 million documents and files, with 51% handling over 10 million (p. 3, 8). Crucially, 92% of participants indicated that unstructured data issues impacted their GenAI initiatives, with 30% describing this impact as "large" or "significant" (p. 4, 8).
- Prevalence of Problematic Data: 68% of respondents in the Shelf & ViB (2025, p. 4, 9) survey said that more than half of all their files had at least one issue, and 42% stated that over 70% of their documents and files had an issue that could hinder GenAI success.
- Common Data Issues: The most frequent problems include duplicate files and multiple versions (66%), out-of-date information (53%), and conflicting versions of files (47%) (Shelf & ViB, 2025, p. 4, 10).
- Primary Data Sources: SharePoint is the primary source of unstructured data for GenAI initiatives (67% of respondents), followed by email (46%) and Microsoft OneDrive (45%) (Shelf & ViB, 2025, p. 4, 9), indicating a reliance on common enterprise systems that may not have been designed with GenAI in mind.
- Addressing Data Issues: While 74% plan to leverage unstructured data despite issues, 55% are planning to address these issues in the next 12-24 months (Shelf & ViB, 2025, p. 4, 10-11). Common approaches include fine-tuning models on existing data (57%) and adding new data management/quality solutions (48%) (Shelf & ViB, 2025, p. 11). The SAS report (2024, p. 11, Insight 1) notes, "Data management and analytics tools can detect outliers and sources of bias in the raw data used to feed LLMs."
2. Governance, Risk, and Compliance (GRC): Effective governance is paramount to manage the risks associated with GenAI, including bias, misinformation (hallucinations), IP infringement, and security vulnerabilities.
- Lack of Preparedness: The SAS report (2024, p. 6) found that only one in ten organizations has undergone the preparation needed to comply with GenAI regulations, and a staggering 95% lack a comprehensive governance framework for GenAI.
- Key Concerns: Data privacy (76%) and security (75%) are top concerns for organizations using GenAI (SAS, 2024, p. 6, 9). McKinsey's survey (2025, p. 7) also shows increasing mitigation efforts for inaccuracy, intellectual property infringement, and privacy risks.
- Monitoring Deficiencies: Only one in twenty organizations (5%) has a reliable system to measure bias and privacy risk in LLMs, and seven in ten (71%) are not able to continuously monitor their GenAI systems (SAS, 2024, p. 6, 11, 12). McKinsey (2025, p. 6) found that only 27% (User Note: Text seems to end here in provided content)
- Leadership Oversight: CEO oversight of AI governance is correlated with higher bottom-line impact. McKinsey (2025, p. 3) reports that 28% of organizations using AI say their CEO is responsible for overseeing AI governance.
- Centralization Models: Risk and compliance, along with data governance for AI, tend to be more centralized, whereas tech talent and adoption of AI solutions are often managed via a hybrid model (McKinsey, 2025, p. 5).
3. Strategic Alignment and Organizational Understanding: A clear strategy and widespread understanding are vital for effective GenAI deployment.
- Understanding Gap: 93% of senior tech decision-makers admit they do not fully understand GenAI or its potential impact on business processes (SAS, 2024, p. 15).
- Prioritization and Best Practices: 66% of companies lack a standard process for prioritizing GenAI use cases (Shelf & ViB, 2025, p. 3, 7). Furthermore, less than one-third of organizations report following most of the 12 key adoption and scaling best practices for GenAI (McKinsey, 2025, p. 9).
- Usage Policies: 39% of organizations do not have a GenAI usage policy in place for their staff (SAS, 2024, p. 15, 16).
4. Technological Integration and Tools: Integrating GenAI into existing systems and workflows can be a significant technical hurdle.
- Tooling and Compatibility: Almost half (47%) of decision-makers report lacking appropriate tools to implement GenAI, and 41% experience compatibility issues when combining GenAI with current systems (SAS, 2024, p. 19).
- Data Set Obstacles: 52% encounter obstacles in using public and proprietary datasets effectively (SAS, 2024, p. 19).
- Technological Limitations as a Barrier: Over a third (34%) state that the biggest challenge to monitoring GenAI is technological limitations (SAS, 2024, p. 19, 21).
5. Talent and Skills: The demand for GenAI-proficient professionals often outstrips supply, although this is evolving.
- In-House Skills Gap: Half of organizations (51%) are concerned they do not have the in-house skills to use GenAI effectively, and 39% have found insufficient internal expertise to be an obstacle to implementation (SAS, 2024, p. 25).
- Evolving Hiring Landscape: McKinsey (2025, p. 11-12) notes that organizations are hiring for new risk-related roles like AI compliance specialists and AI ethics specialists. While hiring for AI-related roles remains challenging, the difficulty has somewhat eased compared to previous years for many roles, with the notable exception of AI data scientists, who remain in high demand.
- Reskilling Efforts: Organizations are increasingly focusing on reskilling their workforce for AI, with many expecting to undertake more AI-related reskilling in the next three years than in the past year (McKinsey, 2025, p. 13).
2.4 The Future of Work with Generative AI
Generative AI is not just a technological advancement; it is a catalyst for fundamental changes in how work is performed, how teams collaborate, and how individuals conceptualize their careers.
- Solopreneurship and Democratization of Tools: The accessibility of powerful GenAI tools is lowering barriers to entry for individuals to start and scale businesses, potentially leading to a rise in solopreneurship and small, agile enterprises.
- Human-GenAI Collaboration (Copilots): The dominant paradigm is shifting towards humans working alongside AI in "copilot" scenarios. AI assists with tasks like drafting, research, coding, and analysis, augmenting human capabilities rather than fully replacing them. McKinsey (2025, p. 19-20) data shows C-level executives are leading the charge in personal GenAI use, potentially modeling this collaborative approach.
- Importance of Human-GenAI Communication (Prompt Engineering): The ability to effectively communicate with GenAI models through well-crafted prompts (prompt engineering) is becoming a critical skill across many roles.
- Workflow Automation: GenAI is enabling deeper automation of workflows at both the company and individual levels. This goes beyond simple task automation to encompass more complex, multi-step processes.
- Emergence of AI Agents: The development of autonomous AI agents capable of understanding goals, planning, and executing complex tasks independently represents a significant future trend. These agents could manage projects, conduct research, or even run aspects of a business with minimal human oversight.
- Workforce Impact and Restructuring: While a plurality of respondents in McKinsey's survey (2025, p. 14) anticipate little immediate change to their workforce size due to GenAI, there are expectations of shifts. Decreased headcount is anticipated in functions like service operations and supply chain/inventory management, while increases are expected in IT and product/service development. The report also notes that headcount reductions, when they occur as a result of GenAI, are one of the organizational attributes with the largest impact on bottom-line value realized (McKinsey, 2025, p. 13).
- Shifting Skill Demands and Continuous Learning: As noted by Lareina Yee, "the difficulty of finding AI talent, while still considerable, is beginning to ease...the long-term workforce effects are still only beginning to take shape" (McKinsey, 2025, p. 15). Continuous learning and adaptation will be key for both individuals and organizations.
As Michael Chui concludes in the McKinsey report (2025, p. 24), "AI only makes an impact in the real world when enterprises adapt to the new capabilities that these technologies enable." This adaptation is an ongoing journey that will define the future of work.
Chapter 3: Communicating with GenAI
3.1 Human-GenAI Communication
The advent of powerful Generative AI (GenAI) models like Gemini 2.5, Claude Sonnet 4.0 & Opus 4.1, and GPT 5 marks a paradigm shift in how humans interact with technology. Beyond mere tools, these AIs are becoming collaborators, assistants, and even creative partners. Central to this evolving relationship is the skill of Human-GenAI communication: the ability to effectively convey intent, guide reasoning, and elicit desired outputs from these complex systems.
The Art and Science of Communicating with AI
In the burgeoning field of AI, the ability to communicate effectively with generative models is rapidly becoming a critical skill. It's not just about typing a question; it's about understanding how these models "think" (or rather, process information and predict sequences), how they interpret language, and how to structure your requests to navigate their vast knowledge and capabilities. This interaction is a two-way street: the AI must understand your needs, and you must learn the "language" that best elicits the AI's strengths. Mastering this communication is not merely beneficial but essential for unlocking the true potential of GenAI.
The importance of such skilled communication cannot be overstated, as it forms the bedrock of successful human-AI collaboration. It is the primary mechanism by which users translate nuanced human intent into explicit instructions that an AI can interpret and act upon. Many aspects of your communication affect its efficacy: the model you use, its training data, its configuration parameters, your word-choice, style and tone, structure, and the context you provide. This is why crafting effective communication is often an iterative process. Inadequate or ambiguous communication can lead to inaccurate, irrelevant, or even nonsensical responses, hindering the AI's ability to provide meaningful assistance and ultimately undermining its utility.
Conversely, effective communication transforms GenAI from a novelty into a powerful tool for diverse applications, ranging from creative content generation and complex problem-solving to nuanced summarization, translation, and sophisticated code development. By clearly defining the task, providing necessary context, and guiding the AI's 'reasoning' process, users can significantly improve the quality, relevance, and utility of the generated outputs. This precision not only maximizes the return on investment in GenAI technologies by ensuring outputs are fit for purpose but also helps in steering the models away from generating unintended biases or nonsensical 'hallucinations,' thereby fostering more reliable and trustworthy AI interactions. The practice of meticulously crafting these instructions is known as prompt engineering, a discipline explored in detail in the next section.
Some might argue that as AI models become "smarter," the need for careful prompting will diminish. While it's true that more advanced models can infer intent better from less precise inputs, the fundamental need for clear communication remains. Think of it this way: a less competent model might be like a bachelor's student, you need to be very explicit and provide a lot of guidance. An advanced model might be like a PhD student, it can understand more nuanced requests and even anticipate some of your needs. However, even with a PhD student, you still need to clearly articulate your research question, your desired methodology, and your expected outcomes to achieve the best results. Similarly, to unlock the full potential of any GenAI model, precise and thoughtful communication is paramount.
Interestingly, individuals with backgrounds in communication, literature, liberal arts, and languages may find themselves at an advantage. These disciplines cultivate skills in articulating complex ideas clearly, understanding nuance and subtext, structuring arguments, and appreciating the power of word choice – all of which are crucial for effective Human-GenAI interaction.
3.2 Prompt Engineering: Crafting Effective Inputs
Prompt engineering is the discipline of designing and refining the input (the "prompt") given to a Large Language Model (LLM) to guide it towards producing the desired output. It's a blend of art and science, requiring both creativity in phrasing and systematic testing of different approaches. Remember, an LLM is a prediction engine; it takes sequential text as input and predicts the most probable next token based on its training. Effective prompt engineering sets up the LLM to predict the right sequence of tokens for your specific task.
Core Concepts of Prompt Engineering:
Several core concepts underpin effective prompting:
- Clarity and Specificity (Instruction):
- Be Clear and Direct: Think of the AI as a new employee needing explicit instructions. Avoid ambiguity. State your request in brief, but specific language.
- Write Clear Instructions: The less the model has to guess, the better. If outputs are too long, ask for brevity; if too simple, ask for expert-level writing.
- Include Details: Provide important details or context. Otherwise, you leave it to the model to guess.
- Simple, Concise Language: Avoid jargon and overly complex sentences.
- Contextualization:
- Provide Context When Necessary: If the request relies on specific knowledge or a particular situation, include that information.
- Provide Reference Text (RAG principles): LLMs can invent fake answers. Providing trusted reference text (like from a database query or document) helps ground the model and reduce fabrications. Instruct the model to use this information.
- Role Assignment / Persona:
- Ask the Model to Adopt a Persona: Assigning a role (e.g., "You are a historian," "Act as a data scientist") can drastically improve output by tailoring tone, style, expertise, and format.
- Providing Examples (Few-Shot, One-Shot, Zero-Shot Learning):
- Zero-Shot: The simplest form, providing only the task description without examples. Relies on the model's pre-trained knowledge.
- One-Shot & Few-Shot: Providing one (one-shot) or multiple (few-shot) examples of the desired input-output pattern. This helps the model understand the task, format, and style. The number of examples depends on task complexity and model capability. Generally, 3-5 examples are a good start for few-shot.
- Quality of Examples: Examples should be relevant, diverse, high-quality, and well-written. A small mistake can confuse the model.
- Structuring Prompts:
- Use Delimiters: Clearly indicate distinct parts of the input (e.g., instructions, examples, context, text to be summarized) using markers like triple quotes, XML tags, or section titles.
- Utilize XML Tags: For structured responses, XML tags can enhance clarity and precision, helping the AI segregate elements of the task.
- Output Format Specification: Explicitly state the desired output format (e.g., bullet points, JSON, table, specific number of paragraphs).
- The Iterative Process (Prompt Development Lifecycle):
- Iterate: Prompt engineering is rarely a one-shot success. Expect to refine and tweak.
- A Common Prompt Development Lifecycle includes steps like:
- Define the Task and Success Criteria.
- Develop Test Cases (including edge cases).
- Engineer the Preliminary Prompt.
- Test Prompt Against Test Cases.
- Refine Prompt.
- Ship the Polished Prompt (and be ready for further iteration).
- Test Changes Systematically: A change might improve isolated examples but worsen overall performance. Define a comprehensive test suite ("eval").
- Document Attempts: Crucial for learning and debugging. Track prompt versions, model settings, and outcomes.
- LLM Output Configuration (Model Parameters):
- Output Length (Max Tokens): Controls how much text the model generates. More tokens mean more computation, cost, and potentially slower responses.
- Sampling Controls:
- Temperature: Controls randomness. Lower values (e.g., 0.1-0.2) for deterministic, factual tasks. Higher values (e.g., 0.7-0.9) for creative, diverse outputs. A temperature of 0 is "greedy decoding."
- Top-K: Selects from the K most likely next tokens.
- Top-P (Nucleus Sampling): Selects from the smallest set of tokens whose cumulative probability exceeds P.
- These settings interact. For example, at temperature 0, Top-K and Top-P become largely irrelevant.
Prompt Engineering Techniques Overview
The following table outlines various specific techniques. These techniques often build upon the core concepts discussed above.
| Technique | Description | Example | Applicable Scenarios |
|---|---|---|---|
| Zero-shot Prompting | This technique asks AI a question or gives a task without providing specific examples. It relies on the model's generalization and pretraining knowledge. Effective for general knowledge queries, but may have limited performance for domain-specific or complex tasks. | "Explain the concept of dark matter and its significance in cosmology." | Testing foundational knowledge, straightforward questions, assessing model generalization ability, and quick information retrieval. |
| Few-shot Prompting | Provides a few relevant question-answer examples before the main query to help the AI understand the task requirements and desired output format. Enhances performance for specific tasks requiring particular formats or styles. | Example 1: Q: What shape is the Earth? A: Spherical. Example 2: Q: What color is Mars? A: Red. Question: What is the size of Jupiter? | Tasks requiring specific formats or styles, helping AI understand specific requirements, and adapting to uncommon or new tasks. |
| Chain of Thought (CoT) | Encourages AI to think step-by-step like humans, showing the entire problem-solving process. Improves accuracy for complex problems and enhances output transparency and explainability. | "Calculate (27 × 14) + (35 × 12). Please explain your calculation process step by step." | Complex math or logical problems, tasks needing detailed reasoning, improving decision transparency, and teaching or instructional scenarios. |
| Tree of Thought (ToT) | An extension of Chain of Thought, allowing AI to explore multiple thinking paths like a decision tree. Useful for open-ended questions or tasks requiring creativity. | "Design a sustainable urban transport system. Propose at least three options, analyze environmental impact, costs, and social benefits, then recommend the best option." | Complex decision-making, tasks requiring multi-angle analysis, creative thinking, strategic planning, and scenarios needing multi-factor trade-offs. |
| Self-consistency | This method is also called majority vote. It is indeed quite clever. Generates multiple independent answers and selects the most common or reasonable one. Increases reliability and stability, especially for questions with multiple possible answers. | "Provide three independent explanations of how global warming affects sea level rise. Compare them and select the most comprehensive and scientific one." | Scenarios requiring high reliability, questions with multiple possible answers, reducing randomness, and improving solution quality for complex problems. |
| Prompt Templates | Creates standardized prompt structures with placeholders for specific content. Improves consistency and efficiency, especially for repetitive tasks. Ensures all necessary details are included while maintaining structure. | Template: "As a [profession], how do you view [topic]? Consider [factor 1] and [factor 2], and provide specific [suggestions/solutions]." Example: "As an environmental scientist, how do you view plastic pollution? Consider marine ecology and human health." | Tasks needing repeated execution, maintaining consistency and structure, and automating the creation of similar but varied prompts. |
| Role-playing Prompts | Requires AI to act as a specific role (e.g., expert, historical figure, or professional) to provide answers or complete tasks. Offers targeted and professional responses from a specific perspective. | "Assume you are Aristotle. Discuss the pros and cons of modern democracy from the perspective of ancient Greek philosophy." | Questions needing specific professional perspectives, simulating expert advice, exploring historical viewpoints, creative writing, and role modeling. |
| Step-by-step Prompting | Breaks complex tasks into a series of simpler steps, guiding AI step-by-step. Each step has clear instructions, ensuring the task is completed accurately and systematically. | "Let us design a mobile app step by step. First, define the app's main features." [Wait for response] "Good, next step: design the primary user interface elements." | Complex processes, teaching or instructional scenarios, multi-step task breakdowns, ensuring each task component receives attention. |
| Reverse Prompting | Asks AI to generate prompts that could lead to a specific output. Helps understand AI's reasoning, generate creative content, or optimize prompt strategies. | "Create a question whose answer is 'Photosynthesis is the process by which plants obtain energy.'" | Creative writing, understanding AI's associative logic, generating test questions, exploring AI knowledge structure. |
| AI Interview Technique | Simulates an interview process by asking AI a series of progressive questions to gather more detailed and accurate preferences. Each question builds on the previous response for in-depth exploration. | "I want to plan a trip. Please ask me questions to understand my preferences for this trip." | Suitable for scenarios where preferences are unclear, gathering detailed information. |
| Thought Provocation | Uses open-ended questions or hypothetical scenarios to stimulate deeper and more creative thinking. Encourages AI to explore novel ideas or solutions, exceeding conventional thinking. | "If humans suddenly gained the ability to read minds, how would society, the economy, and politics change?" | Creative thinking, hypothetical scenario analysis, exploratory problem-solving, stimulating innovative ideas. |
| Meta-prompting | Uses prompts to generate or refine other prompts. This advanced technique involves AI in the creation or optimization of prompts, improving quality and exploring new strategies. | "Design a prompt that effectively guides AI to generate an engaging opening for a historical novel." | Optimizing prompt strategies, exploring AI capabilities, generating task-specific prompts, improving AI system autonomy. |
Advanced Prompting Strategies
Beyond the foundational techniques, several advanced strategies can significantly enhance reasoning and task performance:
- Chain of Thought (CoT) Prompting: Encourages the LLM to generate intermediate reasoning steps before arriving at a final answer, mimicking human problem-solving. This improves accuracy, especially for complex tasks, and provides interpretability.
- Zero-shot CoT: Simply adding "Let's think step by step" can trigger this.
- Few-shot CoT: Providing examples that include the reasoning steps.
- Self-Consistency: An extension of CoT where multiple reasoning paths are generated (often by increasing temperature) for the same prompt, and the most common answer is selected. This improves robustness and accuracy.
- Tree of Thoughts (ToT): Generalizes CoT by allowing the LLM to explore multiple different reasoning paths simultaneously, like branches of a tree, evaluating them and deciding which path to pursue further. Useful for problems requiring exploration or strategic lookahead.
- Step-Back Prompting: Involves prompting the LLM to first consider a more general concept or principle related to the specific task, and then using that abstraction to inform the solution to the original, more specific problem. This helps the model activate broader knowledge.
- ReAct (Reason and Act): Enables LLMs to solve complex tasks by interleaving reasoning steps with action steps. Actions can involve using external tools (like a search engine or code interpreter) to gather information or perform calculations, which then feeds back into the reasoning process. This is a step towards agent-like behavior.
- Giving the Model Time to "Think" / Inner Monologue: Instruct the model to work out its own solution before rushing to a conclusion. For tasks where the reasoning process shouldn't be shared with the end-user (e.g., tutoring), an "inner monologue" can be used, where the reasoning is structured to be parsed out and hidden.
- Using External Tools / Retrieval Augmented Generation (RAG): Compensate for model weaknesses by feeding it outputs from other tools. A text retrieval system (RAG) can provide relevant documents, a code execution engine can run code and do math. Embeddingsbased search is key for efficient knowledge retrieval in RAG.
- Automatic Prompt Engineering (APE): Using an LLM to generate and refine prompts for another LLM or task. This involves generating candidate prompts, evaluating them (e.g., using metrics like BLEU/ROUGE or model-based evaluation), and selecting the best-performing ones.
- Code Prompting: Specific techniques for prompting LLMs to write, explain, translate, or debug code. This includes providing clear requirements, specifying the language, giving examples, and asking for explanations of generated code.
- Multimodal Prompting: Using multiple input formats (text, images, audio, code) to guide an LLM, depending on the model's capabilities.
Best Practices in Prompt Engineering
Synthesizing from expert guidance, here are crucial best practices:
- Be Clear, Concise, and Specific:
- Design with Simplicity: If it's confusing for you, it's likely confusing for the model.
- Be Specific About the Output: Don't be too generic. Specify format, length, style, content focus.
- Use Instructions over Constraints (where possible): Tell the model what to do rather than a long list of what not to do. Constraints are valuable for safety or strict formatting.
- Provide High-Quality Examples: This is often the most impactful practice. Show, don't just tell. Ensure examples are diverse and well-written. For classification in few-shot, mix up the classes in your examples.
- Structure Your Prompt:
- Use Delimiters: To separate instructions, context, examples, and user input.
- Experiment with Input Formats and Writing Styles: Questions, statements, or instructions can yield different results.
- Use Variables in Prompts: For reusability and dynamic input, especially in applications.
- Manage Model Output and Behavior:
- Control Max Token Length: To manage response length, cost, and latency.
- Experiment with Output Formats (e.g., JSON, XML): Structured output can reduce hallucinations and be easier to parse. JSON Repair libraries can help with malformed JSON.
- Working with Schemas (for JSON input/output): Providing a JSON schema for input helps the LLM understand data structure and focus attention.
- Iterate and Evaluate:
- Experiment and Iterate: Try different prompts, analyze results, and refine.
- Test Changes Systematically: Use comprehensive test suites ("evals") to ensure net positive improvements. Evaluate against gold-standard answers if available.
- Document Various Prompt Attempts: Keep detailed records of prompts, model settings (temperature, top-k, top-p, model version), and outputs. This is crucial for learning, debugging, and consistency.
- Adapt to Model Updates: Models evolve. Revisit and adjust prompts to leverage new capabilities or account for changes in behavior.
- Ask for Feedback (from the model itself in conversational contexts): Some advanced interfaces allow you to ask the model to improve your prompt.
- Consider the "Task" and "Who":
- Clearly Define the Task: What do you want the AI to do?
- Assign a Role/Persona: This helps tailor the AI's expertise, tone, and style.
General Source Reference
The insights and techniques discussed in this chapter are synthesized from comprehensive prompt engineering guides and documentation provided by leading AI research organizations and cloud providers, including OpenAI's "Prompt engineering" guide, Anthropic's "Claude Prompt Engineering" resources, Google's "Gemini for Google Workspace Prompting Guide 101," and Google Cloud's "Prompt Engineering" whitepaper by Lee Boonstra, among others. These sources offer in-depth explanations, practical examples, and evolving best practices for interacting effectively with large language models
3.3 Context Engineering: Building the Right Environment
While prompt engineering focuses on crafting the perfect instruction, context engineering represents the next evolution in human-AI interaction. It's about creating the optimal environment for AI models to think and act effectively—preparing the workspace with all necessary tools, references, and background information before the AI begins its work.
Understanding Context Engineering
Context engineering goes beyond writing clever prompts. Traditional prompt engineering emphasizes the right words, tone, and structure to guide model behavior. Context engineering takes a broader approach: providing everything the model needs to understand the situation comprehensively—conversation history, background documents, user preferences, available tools, and real-time data.
The fundamental principle is straightforward: AI models cannot read minds. Without proper context, even the most sophisticated prompt will yield suboptimal results. Context engineering addresses this limitation by ensuring the AI always has complete situational awareness.
Why Context Engineering Matters
Every AI model operates within a "context window"—essentially its short-term memory. Within this limited space, the model must balance your current question, previous messages, relevant facts, and task-specific data. Once this window reaches capacity, the model begins to forget earlier information.
As AI systems grow more sophisticated, prompts alone cannot carry the full burden of communication. A customer service bot must recall past interactions, access account data, and apply current company policies. A coding assistant needs to understand your entire project architecture, not just the individual file being edited. This is where context engineering becomes essential—transforming a single-turn chatbot into a long-term collaborative partner.
How Context Engineering Works
A context-aware AI system relies on several interconnected components that collectively shape what the model perceives and remembers:
- Information Sources:
Context originates from multiple locations: ongoing conversations, user profiles, documents, databases, APIs, available tools, and live data feeds. Each source contributes to the model's understanding of the current situation.
- Dynamic Assembly:
Rather than relying on static templates, context is constructed dynamically for each interaction. The system combines the most relevant, recent, and useful information specifically for that moment, ensuring the model always works with optimal inputs.
- Intelligent Selection:
Not all available information proves helpful. Effective context systems rank and filter what matters—employing semantic search to identify relevant data while discarding noise that might distract the model. This curation ensures focus and efficiency.
- Memory Management:
Short-term memory maintains the current exchange, while long-term memory preserves persistent information—user preferences, established facts, and lessons from past sessions. This dual-memory approach enables the AI to build continuity over time, creating truly personalized experiences.
- Format Optimization:
The presentation of context significantly impacts effectiveness. Concise, well-structured summaries outperform lengthy data dumps. Organized text is far easier for AI to process than unformatted information sprawl. Proper formatting maximizes the utility of limited context windows.
Implementing Context Engineering
Building robust context systems requires balancing memory limitations with performance demands. Four core strategies provide the foundation:
- Write: Create and Save Context
Provide your AI with a comprehensive notebook. Store system instructions (e.g., "You are a helpful legal assistant who writes concise summaries"), maintain scratchpads for temporary thoughts, and establish long-term memory to preserve key facts across sessions. This written context serves as the AI's reference library.
- Select: Retrieve What's Relevant
Extract only necessary information for each task. Retrieval-Augmented Generation (RAG) searches documents or databases to find fresh, specific information relevant to the current query—such as fetching the latest return policy before answering a customer's question. Effective systems also identify appropriate tools and prioritize context by importance or recency.
- Compress: Reduce Context Size
Preserve essential information while eliminating unnecessary details. Summarization condenses lengthy conversations into key points. Trimming removes outdated or irrelevant content. Entity extraction captures crucial names, dates, and facts for later reference. These compression techniques maximize the utility of limited context windows.
- Isolate: Partition Context
Separate different types of work to prevent interference. Multi-agent architectures can delegate tasks to specialized sub-agents, each maintaining its own focused context. Session separation keeps planning, coding, and debugging in distinct threads, preventing confusion and maintaining clarity across different work streams.
Practical Tactics for Context Engineering
Implementing context engineering doesn't require extensive resources. These practical habits can significantly improve AI interactions:
- Be Specific: Vague inputs invariably produce vague outputs. Precision in context leads to precision in results.
- Show Examples: Demonstrations consistently outperform abstract descriptions in conveying requirements.
- State Expectations Clearly: Explicitly communicate what's required, what's optional, and what constitutes quality output.
- Iterate Systematically: Start with minimal context, test thoroughly, then expand based on results.
- Keep Context Fresh: Regularly update reference materials to ensure accuracy and relevance.
- Log Everything: Track how the AI utilizes tools, retrieves data, and where errors occur. This documentation proves invaluable for optimization.
- Avoid Ambiguity: If an instruction permits multiple interpretations, the AI will likely choose unexpectedly.
- Balance Flexibility and Control: Determine when creative freedom serves your goals and when strict reliability is paramount.
Context Engineering vs. Prompt Engineering
Prompt engineering and context engineering are complementary disciplines, not competing approaches. Prompt engineering addresses what you say to the AI. Context engineering determines what the AI knows when you speak.
Consider prompt engineering as providing directions to a destination. Context engineering represents the GPS system—continuously updating with traffic conditions, detours, and your preferences. Perfect prompts cannot compensate for inadequate context. Conversely, with rich, well-managed context, even simple prompts can produce remarkable results.
The Strategic Importance of Context
Context engineering marks a fundamental shift in AI development and deployment. Rather than optimizing individual prompts, we design systems that continuously provide AI with optimal information at optimal times.
The quality of AI output directly correlates with input quality. By carefully curating what the AI perceives and remembers, context engineering transforms AI from an occasionally helpful tool into a consistently reliable partner. As AI becomes integral to daily operations—from customer support to research and strategic decision-making—those who master context engineering will shape how these systems think, learn, and collaborate with humans.
The future of effective AI interaction lies not in finding perfect prompts, but in building perfect context. This represents the next frontier in human-AI collaboration, where thoughtfully engineered environments enable AI to achieve its full potential as a transformative business tool.
Part II
Tools and Applications
Understanding GenAI models, tools, and how they apply across business functions
Chapter 4: Large language models and tools
Large Language Models (LLMs) have fundamentally transformed how we approach natural language processing and understanding. By synthesizing enormous datasets and leveraging sophisticated neural architectures, these models enable a variety of applications, from drafting text to solving complex problems in specialized fields. This chapter aims to provide a detailed comparison of some of the most notable LLMs currently available, including OpenAI's GPT series, Anthropic's Claude, Google's Gemini series, Deepseek, and Grok. Moreover, we will explore integrated platforms, playgrounds for experimentation, and options for local deployment of models.
4.1 Leading Commercial Models: OpenAI, Anthropic, and Google
4.1.1 OpenAI's GPT Series: Pushing the Boundaries
OpenAI's offerings have continually advanced, with the GPT series representing the current state-of-the-art. GPT build on previous models by significantly enhancing architecture and parameters, resulting in superior capabilities for contextual understanding, multimodal processing (text, image, audio), and nuanced language generation. GPT-5, in particular, offers improved speed and cost-effectiveness compared to GPT-o3, while matching its high intelligence level. These models manage complex tasks, hold longer conversations effectively due to large context windows, and display enhanced creativity and reliability across various subject matters.
For tasks prioritizing efficiency and cost, OpenAI offers models like GPT-5 mini. It retains strong language generation and understanding capabilities but operates with fewer parameters and potentially smaller context windows compared to the flagship models. This makes GPT-4o mini a suitable choice for less demanding scenarios where speed and cost are primary concerns, excelling in environments requiring faster feedback loops or handling high volumes of simpler tasks.
The comparison within the GPT series often involves balancing raw capability against efficiency and cost (GPT-4o mini).
4.1.2 Anthropic's Claude Series: Focus on Enterprise and Safety
Anthropic's Claude series, culminating in models like Claude Sonnet, emphasizes safe, coherent, and reliable language output. Claude models are characterized by their strong performance in complex reasoning, coding, and writing tasks, alongside a focus on reducing harmful responses and maintaining alignment with user intent (Constitutional AI). This makes them well-suited for enterprise applications, professional services, and customer-facing environments where dependability and safety are paramount.
Claude Sonnet offers a balance of intelligence, speed, and cost, demonstrating strong capabilities in areas like programming and creative writing. It features a very large context window and introduces "App Preview," allowing interaction with external tools and APIs. While perhaps less focused on multimodality compared to GPT or Gemini, Claude excels in sophisticated text-based reasoning and generation, making it a strong contender for complex professional workflows.
4.1.3 Google's Gemini Series: Multimodality and Research Integration
Google's Gemini series, including Gemini Pro, emphasizes strong multimodal capabilities from the ground up. These models are engineered to effectively integrate and reason across text, images, video, and audio inputs. Gemini models feature extremely large context windows (up to 2 million tokens experimentally), enabling deep analysis of extensive documents, codebases, or multimedia content. Gemini Pro aims to be particularly efficient, offering high performance at potentially lower costs.
Google also leverages its AI advancements in specialized research tools. NotebookLM acts as a personalized research assistant, grounding its responses in user-provided source materials for enhanced accuracy and trustworthiness. Furthermore, Google explores concepts like the "AI Co-scientist," aiming to accelerate scientific breakthroughs by having AI assist directly in the research process, from hypothesis generation to data analysis (https://research.google/ blog/accelerating-scientific-breakthroughs-with-an-ai-co-scientist/).
4.2 Other Notable Models and Platforms
Beyond the "big three," other significant players are emerging with distinct focuses.
4.2.1 Deepseek: Open Source Powerhouse
Deepseek has gained prominence with models like Deepseek-V3, an open-source Mixture-of-Experts (MoE) model. It offers performance competitive with leading proprietary models, particularly in coding and reasoning tasks, but at a significantly lower cost due to its open nature and efficient architecture. Deepseek's commitment to open source makes its models highly attractive for researchers and developers seeking customization, transparency, and lower operational expenses.R1 is a reasoning model and attract a lot of attention as well. Although the development of R2 is very slow. We would expect it may again surprise us in terms of its performance.
4.2.2 Grok: Real-time Information and Conversational Style
Developed by xAI, Grok aims to differentiate itself with a conversational style often described as witty or rebellious, and access to real-time information, primarily through integration with the X (formerly Twitter) platform. This focus makes it potentially useful for understanding current events, trends, and public discourse.
4.3 Integrated platforms
Platforms that integrate multiple generative AI models offer users the flexibility to interact with various LLMs through a single interface, each catering to specific needs and preferences. These platforms enhance accessibility and streamline the user experience by consolidating diverse AI capabilities.
4.3.1 Poe
Developed by Quora, Poe serves as a centralized platform providing access to multiple AI chatbots, including models such as GPT-4, Claude, and others. It is designed to facilitate seamless interactions with various AI models, allowing users to ask questions, receive instant answers, and engage in back-and-forth conversations.
4.3.2 Coze
Coze is a next-generation AI application and chatbot development platform that enables users, regardless of programming experience, to create and deploy customized chatbots across different social platforms and messaging apps. It focuses on personalization, allowing for adaptation to user-specific preferences and learning from repeated interactions to provide a tailored conversational experience.
4.3.3 Perplexity AI
Perplexity AI is a conversational search engine that combines large language models with search capabilities to provide concise and accurate answers to user queries. It integrates information retrieval with generative AI, allowing users to obtain direct answers to their questions, supported by cited sources.
4.3.4 ChatOne
ChatOne integrates multiple AI models, including GPT, Claude Sonnet, Claude Opus, as well as Gemini models. It allows users to compare responses from different AI chatbots in one place, facilitating a comprehensive understanding of various AI outputs.
4.3.5 You.com
You.com is a search engine that offers a chat-first AI assistant experience while still providing web search capabilities. It introduced AI Modes to offer a tailored interaction experience through its platform, allowing users to switch between various leading AI models, such as OpenAI's GPT, Anthropic's Claude Sonnet & Opus, Google's Gemini, and Llama.
These platforms exemplify the trend of integrating multiple generative AI models into unified interfaces, enhancing user experience by providing diverse AI capabilities tailored to individual needs.
4.4 Playgrounds
Platforms designed to provide access to generative AI models serve as essential tools for developers, researchers, and businesses aiming to explore and test cutting-edge AI technologies. These platforms, such as OpenAI Playground, Google AI Studio, NVIDIA AI Playground, IBM watsonx.ai, and Hugging Face, offer user-friendly interfaces to interact with advanced language models like Llama 3.1, Zephyr, and others. By enabling experimentation with prompts, fine-tuning capabilities, and integration options, they simplify the process of leveraging generative AI for diverse applications. Many of these platforms offer free tiers or trials, fostering accessibility while supporting innovation in AI-driven projects. Their role in democratizing AI aligns with the growing demand for efficient, scalable, and personalized AI solutions across industries.
4.4.1 LLMs arena
LLMs Arena (https://lmsarena.ai/) allows users to directly compare several language models by inputting identical prompts and assessing each model's performance side by side. This open-access resource provides a transparent means of determining which model may best suit specific needs, be it conversational fluency, response accuracy, or domain-specific expertise.
4.4.2 Nvidia build platform
Nvidia's LLM comparison platform (https://build.nvidia.com/) also serves a critical function in helping users evaluate and benchmark language models. Leveraging Nvidia's expertise in hardware acceleration, this platform allows the efficient assessment of different LLMs in terms of speed, accuracy, and efficiency across various tasks.
4.4.3 Google AI Studio
Google AI Studio (https://aistudio.google.com/) offers yet another venue for comparing Google's suite of LLMs, such as Gemini, against other available models. These platforms provide not only benchmarks but also insight into how specific models perform under conditions like limited compute power or handling complex user queries.
4.4.4 Hugging Face
Hugging Face is a platform that hosts a wide array of AI models, including Llama 3.1 and Zephyr. Users can access and test these models through the platform's interface. Hugging Face offers free access to many models, with options for subscription plans that provide additional features.
These platforms provide valuable resources for users interested in exploring and testing generative AI models, each offering unique features and access levels.
4.4.5 OpenAI Playground
OpenAI provides an interactive web-based interface called the OpenAI Playground, allowing users to experiment with their language models, including GPT-3 and GPT-4. Users can input prompts and observe the models' responses in real-time. While OpenAI offers free access with usage limitations, extended access may require a subscription.
4.4.6 IBM watsonx.ai
IBM's watsonx.ai is an enterprise-ready AI studio that offers access to a selection of foundation models, including IBM's own Granite series and other open-source models. Users can build, train, and deploy AI models using this platform. IBM offers a free trial for watsonx.ai, allowing users to explore its capabilities.
4.5 Local Deployment of Language Models
Access to sophisticated language models is often constrained by financial or computational barriers, prompting the development of free alternatives. These alternatives allow users to interact with LLMs without incurring significant costs, albeit with trade-offs in sophistication, accuracy, or data privacy.
For individuals or institutions that prioritize data security and customization, deploying language models locally remains an attractive option. Tools such as LMStudio and Ollama enable users to run LLMs on local servers or personal hardware, circumventing privacy concerns associated with sending data to third-party servers. Local deployment can be particularly advantageous for sectors like healthcare or finance, where privacy and compliance are paramount. Open source models such as Llama 3, developed by Meta, provide open-access models that can be deployed and used for research, education, and limited commercial use. Though these models may not rival GPT-4 in terms of processing power or depth, they provide considerable functionality at no cost, making them particularly useful in educational settings and non-profit applications.
Another noteworthy free alternative is Mixtral by Mistral AI. Mixtral offers competitive performance for basic language understanding and generation tasks. While its dataset size and parameter count are smaller compared to commercially available models, it still offers value by democratizing access to NLP technology.
LMStudio provides a streamlined platform for deploying smaller, fine-tuned versions of major LLMs, ensuring that enterprises can meet their unique requirements without relying on third-party infrastructure. By offering the possibility of adjusting models to specific needs, LMStudio delivers control over both data and model behavior.
Ollama, another local deployment option, emphasizes ease of use. Designed for those with limited technical expertise, it provides user-friendly deployment scripts and pre-configured environments. These attributes make Ollama a compelling option for small businesses and individual researchers aiming to leverage the power of LLMs without substantial investments in hardware or specialized talent.
4.5.1 Tutorial:
To install and run generative AI models like Llama 4 in LM Studio, follow these steps:
- Download LM Studio: Visit the LM Studio website and download the installer compatible with your operating system.
- Install LM Studio: Run the downloaded installer and follow the on-screen instructions to complete the installation.
- Launch LM Studio: Open the application after installation.
- Download the Llama 4 Model:
- Navigate to the 'Search' tab within LM Studio.
- Enter "Llama 4" in the search bar.
- Select the desired model variant (e.g., Llama 3.1 8B Instruct).
- Click 'Download' to initiate the model download.
- Load the Model:
- After the download completes, go to the 'AI Chat' section.
- Click on 'Select a model to load' and choose the downloaded Llama 3 model.
- The model will load, allowing you to interact with it through the chat interface.
Ensure your system meets the necessary requirements for running large language models to achieve optimal performance.
Chapter 5: API integration
5.1 Understanding APIs
An Application Programming Interface (API) is a set of protocols and tools that allow different software applications to communicate and share functionalities. APIs enable developers to integrate external services or data into their applications without building those services from scratch.
Why and When We Use APIs:
- Integration of Services: APIs allow different software systems to work together by enabling them to share data and functionalities. For example, a weather app on your phone integrates weather data from an external service through an API, saving time and resources.
- Extending Functionality: APIs help developers add advanced features to applications without building them from scratch. For instance, a company might use payment gateway APIs (like Stripe or PayPal) to incorporate secure payment processing.
- Automation and Efficiency: APIs enable automation by allowing applications to communicate without manual intervention. For example, APIs can automate workflows, such as synchronizing CRM software with email marketing platforms.
- Data Sharing: APIs provide standardized ways to share data between applications, making it easier to build tools that depend on external or internal datasets.
Why APIs Are Needed in a Company Context:
- Streamlined Operations: Companies use APIs to connect various internal systems, such as HR, CRM, and inventory management tools, ensuring consistent and efficient workflows.
- Scaling and Innovation: APIs allow businesses to access and integrate third-party services, such as AI tools, analytics platforms, or cloud computing resources, to scale operations and stay competitive.
- Customer Experience: APIs power customer-facing applications by integrating features like chat support, location services, and payment processing, enhancing user experience and satisfaction.
- Collaboration: In large organizations, APIs enable different departments or teams to access and use shared services, fostering collaboration without duplicating efforts.
Why APIs Are Useful in a Personal Context:
- Simplifying Daily Tasks: APIs allow personal applications to access useful services, like weather forecasts, navigation, or financial tracking, seamlessly integrating them into daily routines.
- Customization: Individuals can use APIs to personalize their tools or automate tasks. For example, APIs in platforms like IFTTT or Zapier let users create workflows to connect their favorite apps.
- Learning and Experimentation: APIs are invaluable for students, developers, and hobbyists who want to experiment with building projects, accessing external services, or learning about programming.
5.2 Implementation steps
Implementing an API involves several steps:
- Understanding Requirements: Clearly define the functionalities needed and identify suitable APIs that provide these services.
- Accessing Documentation: Review the API's documentation to comprehend its capabilities, endpoints, authentication methods, and usage limitations.
- Obtaining Access Credentials: Register with the API provider to receive necessary credentials, such as API keys or tokens, which authenticate your application's requests.
- Integrating the API: Write code to send requests to the API's endpoints and handle the responses appropriately within your application.
- Testing and Monitoring: Conduct thorough testing to ensure the API integration functions as intended and monitor its performance for any issues.
Tutorial:
- Sign Up or Log In: Visit OpenAI's website and create an account or log in to your existing account.
- Access API Documentation: Navigate to the API section to understand its usage, pricing, and capabilities.
- Create an API Key: In your OpenAI account dashboard, go to the API Keys section. Click "Create API Key" to generate a key specific to your account.
- Choose a Pricing Plan: Select a plan that fits your usage. OpenAI offers pay-as-you-go pricing with specific rates for different models like GPT-3.5 or GPT-4.
- Test the API: Use tools like Postman or OpenAI's Playground to test the API. Include your API key in the headers for authentication.
- Start Integration: Implement the API in your application by using the key and endpoints provided in the documentation.
5.3 Pricing and strategy
API pricing models vary among providers and may include:
- Pay-as-you-go: Charges are based on the number of API calls made. For instance, Amazon API Gateway offers pricing as low as $0.90 per million requests at higher usage tiers.
- Tiered Plans: Different pricing tiers offer varying levels of access and features. For example, Microsoft Azure's API Management provides several tiers, including Developer, Basic, Standard, and Premium, each with distinct pricing and capabilities.
- Subscription Models: Fixed monthly or annual fees grant access to a set number of API calls or features. Postman offers plans ranging from free for individuals to enterprise plans for larger organizations.
You may use this tool to calculate the price: https://yourgpt.ai/tools/openai-and-other-llm-api-pr
| Provider | Model | Context | Input/1k Tokens | Output/1k Tokens | Per Call | Total |
|---|---|---|---|---|---|---|
| OpenAI | GPT-3.5 Turbo | 16k | $0.0005 | $0.0015 | $0.0020 | $0.20 |
| OpenAI | GPT 5 | 128k | $0.01 | $0.03 | $0.0400 | $4.00 |
| OpenAI | GPT-4o (omni) | 128k | $0.005 | $0.015 | $0.0200 | $2.00 |
| OpenAI | GPT-4o mini | 128k | $0.00015 | $0.0006 | $0.0007 | $0.07 |
| OpenAI | GPT-4 | 8k | $0.03 | $0.06 | $0.0900 | $9.00 |
| OpenAI | GPT-4 | 32k | $0.06 | $0.12 | $0.1800 | $18.00 |
| OpenAI | GPT-3.5 Turbo | 4k | $0.0015 | $0.002 | $0.0035 | $0.35 |
| Mistral AI | Mixtral 8x7B | 32k | $0.0007 | $0.0007 | $0.0014 | $0.14 |
| Mistral AI | Mistral Small | 32k | $0.002 | $0.006 | $0.0080 | $0.80 |
| Mistral AI | Mistral Large | 32k | $0.008 | $0.024 | $0.0320 | $3.20 |
| Meta | Llama 2 70b | 4k | $0.001 | $0.001 | $0.0020 | $0.20 |
| Meta | Llama 3.1 405b | 128k | $0.003 | $0.005 | $0.0080 | $0.80 |
| PaLM 2 | 8k | $0.002 | $0.002 | $0.0040 | $0.40 | |
| Gemini 2.5 Flash | 1M | $0.0007 | $0.0021 | $0.0028 | $0.28 | |
| Gemini 1.0 Pro | 32k | $0.0005 | $0.0015 | $0.0020 | $0.20 | |
| Gemini 2.5 Pro | 1M | $0.007 | $0.021 | $0.0280 | $2.80 | |
| DataBricks | DBRX | 32k | $0.00225 | $0.00675 | $0.0090 | $0.90 |
| Anthropic | Claude Instant | 100k | $0.0008 | $0.0024 | $0.0032 | $0.32 |
| Anthropic | Claude 2.1 | 200k | $0.008 | $0.024 | $0.0320 | $3.20 |
| Anthropic | Claude 3 Haiku | 200k | $0.00025 | $0.00125 | $0.0015 | $0.15 |
| Anthropic | Claude Sonnet 4.0 | 200k | $0.003 | $0.015 | $0.0180 | $1.80 |
| Anthropic | Claude Opus 4.1 | 200k | $0.015 | $0.075 | $0.0900 | $9.00 |
| Amazon | Titan Text - Lite | 4k | $0.00015 | $0.0002 | $0.0003 | $0.03 |
| Amazon | Titan Text - Express | 8k | $0.0002 | $0.0006 | $0.0008 | $0.08 |
5.4 Applications across domains
GenAI APIs have diverse applications across various domains: In web development, generative AI APIs enhance user engagement by creating dynamic content such as personalized recommendations, automated customer support chatbots, or real-time language translation features. These APIs can also generate tailored web copy or UI designs, streamlining the development process.
For mobile applications, generative AI APIs power functionalities such as voice-to-text conversions, AI-driven virtual assistants, or content creation tools that adapt to user preferences. They enable applications to dynamically generate text summaries, personalized messages, or interactive narratives, enhancing the user experience.
In data analysis, generative AI APIs help transform complex data into human-readable narratives, generate automated insights, and even create visualizations from raw datasets. This enables businesses to better understand their data and communicate findings effectively without the need for extensive manual interpretation.
For the Internet of Things (IoT), generative AI APIs enable smarter communication between devices by generating contextual insights and predictive suggestions. For example, an IoT system managing energy consumption could use a generative AI API to create detailed, customized reports for users or suggest actions to optimize efficiency.
A generative AI API can significantly enhance efficiency in business contexts, particularly in areas like customer support and content creation, by providing sophisticated automation and personalization capabilities.
Consider a company aiming to improve its customer support system. By integrating a generative AI API, the company can create an intelligent chatbot capable of handling a broad range of inquiries. Unlike traditional rule-based chatbots, the generative AI-powered system can understand nuanced language, provide contextually accurate responses, and even simulate empathetic interactions. For example, if a customer asks about the status of a shipment, the AI can access relevant backend systems, retrieve the latest tracking data, and communicate it in a human-like manner. Beyond answering routine queries, the AI can identify complex issues and escalate them with detailed summaries to human agents, ensuring smoother transitions and reducing resolution times. This approach not only improves customer satisfaction but also allows human agents to focus on higher-value tasks, thus optimizing overall resource allocation.
In a personal context, generative AI APIs can revolutionize creative processes, such as writing. Take the case of a freelance writer tasked with producing high-quality blog posts on diverse topics within tight deadlines. Using a generative AI API, the writer can streamline the ideation phase by generating outlines or even full drafts based on a simple prompt. The AI provides structured and contextually relevant content that serves as a strong starting point, enabling the writer to focus on refining and personalizing the material. This process not only accelerates delivery but also ensures that the output meets professional standards. Moreover, the AI can adapt to specific tones or styles, allowing the writer to cater to different client needs without sacrificing quality.
Chapter 6: Specialized tools for various tasks
In today's rapidly evolving workplace, generative AI tools are transforming how we work, creating opportunities for enhanced productivity and innovation across various professional domains. These tools serve as powerful allies, augmenting human capabilities rather than replacing them, and enabling professionals to focus on higher-value tasks that require creativity, critical thinking, and emotional intelligence.
Content creation has been revolutionized by AI-powered platforms that assist in generating, editing, and optimizing various forms of content. From crafting compelling marketing copy to creating engaging visual assets, these tools help maintain consistent output while reducing the time spent on routine creative tasks. Writers, marketers, and creative professionals can now produce high-quality content more efficiently, allowing them to focus on strategy and creative direction.
In the realm of professional support, AI tools are streamlining administrative tasks and enhancing decision-making processes. These solutions handle everything from meeting management to complex project planning, providing intelligent assistance that helps professionals stay organized and focused. The technology excels at automating routine communications, scheduling, and documentation tasks that traditionally consumed valuable time.
Research and analysis have become more sophisticated with AI-powered platforms that can process vast amounts of information quickly and effectively. These tools help researchers and analysts uncover insights, identify patterns, and make data-driven decisions with greater confidence. They excel at literature reviews, market analysis, and data interpretation, significantly reducing the time required for comprehensive research.
Technical assistance has evolved to include intelligent coding companions and infrastructure management tools. Software developers and IT professionals now have access to AI-powered solutions that can generate code, identify bugs, and maintain systems more efficiently. These tools not only accelerate development cycles but also help maintain code quality and security standards.
The integration of these AI tools into professional workflows represents a significant shift in how work gets done. As platforms like "There's An AI For That" and GAIforResearch.com continue to expand their databases and improve their matching capabilities, professionals have unprecedented access to task-specific AI solutions. This technological evolution is not just about automation; it's about augmenting human capabilities and enabling professionals to achieve more while focusing on what they do best.
GAIforResearch.com stands as a specialized initiative focused on integrating generative AI into academic and research workflows. The platform offers a curated selection of AI tools specifically tailored for research purposes.
The platform's toolkit is organized into six key research-focused categories:
- Proofreading tools for academic writing enhancement
- Content generation for research documentation
- Coding and data analysis support
- Text analysis capabilities
- Literature management solutions
- Specialized search engine tools
A unique feature of the platform is Mimi, an AI assistant available across multiple platforms including GPT Store, Poe, Yuanqi, and COZE. Mimi serves as an intelligent matchmaker, helping researchers identify the most suitable AI tools for their specific research needs and providing guidance on tool usage.
"There's An AI For That" (TAAFT) is a comprehensive platform that aggregates a vast array of artificial intelligence tools, facilitating users in discovering AI solutions tailored to specific tasks. As of November 2024, TAAFT hosts a database of over 23,000 AI tools, encompassing more than 15,600 distinct tasks.
The platform offers a user-friendly interface with features such as a smart AI search system, enabling efficient navigation through its extensive catalog. Users can explore AI tools categorized by tasks, access featured AI solutions, and stay informed about the latest developments in the AI landscape.
In addition to its tool directory, TAAFT provides resources like the Global Job Impact Index, which assesses AI's influence on various professions, offering insights into the evolving dynamics between AI technologies and the workforce.
TAAFT also fosters a community for AI builders and users, encouraging collaboration and knowledge sharing among individuals engaged in AI development and application.
6.1 Content creation
6.1.1 Text Generation
Writing assistants
ChatGPT with canvas stands at the forefront of AI language models, offering unprecedented capabilities in understanding and generating human-like text. It excels in complex writing tasks, from creative storytelling to technical documentation, and can seamlessly switch between different writing styles and tones. The model's strength lies in its ability to understand context deeply and generate coherent, well-structured content across various domains.
Claude, developed by Anthropic, distinguishes itself through its nuanced understanding and ethical considerations. It particularly shines in academic writing and detailed analysis, offering well-reasoned responses that maintain intellectual rigor. The model excels at handling complex instructions and can engage in sophisticated dialogue while maintaining consistency and accuracy.
Google Gemini represents the latest advancement in multimodal AI, combining language understanding with visual comprehension. Its ability to process and generate content based on both text and visual inputs makes it uniquely powerful for content creators who work across different media formats. The model shows particular strength in technical and analytical tasks.
Specialized Writing Platforms:
Jasper.ai has revolutionized marketing content creation with its intuitive platform designed specifically for marketing professionals. The platform combines powerful AI writing capabilities with marketing-focused templates and frameworks. Users can maintain consistent brand voice across all content while leveraging built-in SEO optimization tools. The platform's team collaboration features make it ideal for marketing departments and agencies managing multiple clients and campaigns.
Copy.ai specializes in crafting compelling sales copy that converts. The platform excels in generating attention-grabbing headlines, persuasive email campaigns, and engaging product descriptions. Its strength lies in understanding marketing psychology and applying it to generate copy that resonates with target audiences. The platform offers an extensive template library covering various marketing scenarios and customer touchpoints.
WriteSonic focuses on creating comprehensive, SEO-optimized content for digital platforms. The tool stands out for its ability to generate factually accurate, well-researched articles that maintain readability and engagement. Its multilingual capabilities make it valuable for global content strategies, while its fact-checking features ensure content reliability.
QuillBot specializes in content optimization through advanced paraphrasing and rewriting capabilities. Its strength lies in maintaining the original message while improving clarity and engagement. The tool offers multiple writing modes to match different stylistic needs and communication contexts.
DeepL is a neural machine translation service launched in August 2017 by the Cologne-based company DeepL SE. It utilizes convolutional neural networks trained on the Linguee database to deliver translations that are often more natural and accurate than those produced by competing services. As of 2024, DeepL supports 33 languages, including English, German, French, Spanish, Italian, Dutch, Polish, Russian, Chinese (simplified and traditional), Japanese, Korean, and Norwegian. The service offers both a free version, with a character limit per translation, and a subscription-based DeepL Pro, which provides enhanced features such as unlimited text translation, document translation capabilities, and integration options for professional use.
6.1.2 Image Generation
Text-to-Image Models:
DALL-E represents OpenAI's latest breakthrough in AI image generation, setting new standards for photorealistic output and prompt interpretation. The system excels in understanding nuanced textual descriptions and translating them into visually stunning images with remarkable accuracy. Its ability to maintain consistency in style, perspective, and lighting makes it particularly valuable for professional creative work. The platform's commercial rights policy and content safety filters make it suitable for business applications, while its intuitive interface allows both beginners and professionals to achieve professional-grade results.
Midjourney has carved out a unique position in the AI art space with its distinctive aesthetic quality and artistic interpretation capabilities. The platform's strength lies in its ability to generate highly stylized, emotionally resonant images that often surpass human expectations. Its active community serves as both a learning resource and inspiration hub, while the platform's discord-based interface creates a unique collaborative environment. The latest version shows remarkable improvements in human anatomy, text rendering, and compositional understanding.
Stable Diffusion has revolutionized the accessibility of AI image generation through its open-source nature. The platform offers unprecedented flexibility for technical users who wish to fine-tune models for specific use cases or deploy locally for enhanced privacy and control. Its active development community continuously produces new models and improvements, while its integration capabilities make it ideal for custom applications and enterprise solutions. The platform supports various implementations, from web interfaces to local installations, catering to different technical expertise levels.
Specialized Visual Tools:
Canva with Magic Studio has transformed the graphic design landscape by combining its user-friendly interface with powerful AI capabilities. The platform integrates AI image generation seamlessly with its extensive template library and design tools, making professional-grade design accessible to non-designers. Its Magic Studio features extend beyond basic image generation to include background removal, image expansion, and text-to-image design elements. The platform's strength lies in its comprehensive approach to brand management, allowing teams to maintain consistent visual identity across all content.
Adobe Firefly has emerged as a game-changer in professional creative workflows by integrating generative AI capabilities within the familiar Adobe Creative Suite environment. The platform's unique selling point is its use of licensed training data, ensuring commercial safety for professional use. Firefly excels in understanding design context and maintaining professional standards while offering innovative features like style transfer and texture generation. Its seamless integration with other Adobe products creates a powerful ecosystem for creative professionals.
Image Editing Specialists:
Google Imagen 3 represents Google DeepMind's latest advancement in AI image generation and editing, available through Vertex AI, ImageFX, and Gemini. Released in 2024 with continuous improvements, Imagen 3 excels in photorealistic image creation and sophisticated editing capabilities. The platform's standout features include mask-based inpainting and outpainting, allowing users to add or remove objects with surgical precision. Its advanced editing capabilities support product background replacement, content expansion beyond original boundaries, and detailed object manipulation. What sets Imagen 3 apart is its ability to handle complex editing instructions while maintaining lighting consistency, perspective accuracy, and natural blending. The platform uses SynthID watermarking for authenticity verification and supports multiple resolution outputs up to 1080p. Its integration with Google's ecosystem makes it particularly powerful for enterprise applications requiring scalable, production-grade image editing.
nano banana (powered by Google's Gemini 2.5 Flash) has emerged as a revolutionary text-based image editing tool that eliminates the need for complex manual editing workflows. The platform's defining characteristic is its ability to understand and execute natural language editing commands with exceptional consistency. Users can simply describe desired changes—"place in a blizzard," "change outfit to formal wear," or "make background sunset"—and the AI seamlessly applies these edits while preserving character identity, facial features, and scene coherence across multiple iterations. This makes it invaluable for creating consistent AI influencer content and UGC-style materials. nano banana excels in character consistency, maintaining stable faces and features even through repeated edits—a critical advantage for content creators building branded characters or narrative series. The platform supports advanced capabilities including novel view synthesis (generating new angles from a single photo), style transfer, scene transformation, and multi-image composition. Its millisecond-to-seconds generation speed, combined with automatic edit history tracking and a conversational interface, makes professional-grade image editing accessible to non-technical users. The platform's strength lies in understanding contextual instructions and producing coherent, commercially viable results suitable for social media, marketing campaigns, and creative projects.
6.1.3 Video Generation
AI Video Generators:
OpenAI Sora 2 represents a major breakthrough in AI video generation, launched in September 2025 as the "GPT-3.5 moment" for video creation. Sora 2 excels in generating physically accurate, realistic videos with synchronized audio generation—a first-of-its-kind capability in the industry. The platform's standout feature is its advanced physics simulation: basketballs bounce realistically off backboards, gymnasts perform authentic routines with proper biomechanics, and objects behave according to real-world physics rather than morphing to fulfill prompts. Sora 2 introduces groundbreaking features including the Cameo capability, allowing users to insert their own likeness and voice into generated environments through consent-based self-recording. The platform maintains scene state and character continuity across multiple shots, enabling coherent narratives with consistent lighting, objects, and motion. With support for resolutions up to 1920×1080 and durations of 1-20 seconds, Sora 2 combines visual excellence with automatically generated soundscapes, speech, and effects that sync seamlessly with visuals. Available through the Sora iOS app and sora.com with free tier access, it includes robust safety features including watermarking, identity verification, and content filtering.
Google Veo 3 represents Google's significant advancement in AI video generation technology. This model is designed to create high-quality, coherent, and controllable video from text, image, or video prompts, setting new benchmarks in the field. Veo's distinctive capability lies in its simultaneous audio and video generation, creating synchronized soundscapes that match the visual content. The platform excels in understanding complex prompts and translating them into cinematic-quality output with sophisticated camera movements and scene composition. Its integration with Google's ecosystem makes it particularly powerful for enterprise applications requiring scalable video production.
Seedance 1.0 (ByteDance) has emerged as the leader in cinematic-quality AI video generation, particularly excelling in multi-shot storytelling with consistent characters, lighting, and aesthetics across scenes. Launched in June 2025, Seedance's standout feature is its native multi-shot capability—no manual editing required—enabling creators to produce cohesive narratives automatically. The platform delivers 1080p native resolution at 24 FPS with impressive generation speeds of approximately 41 seconds for a 5-second clip on NVIDIA L20 hardware, representing a 10x inference speedup through multi-stage distillation. Seedance supports multiple aspect ratios (1:1, 4:3, 16:9, 21:9) and excels in cinematic camera movements including pans, zooms, tracking shots, and aerial views. Its top rankings on the Artificial Analysis Video Arena Leaderboard for both text-to-video and image-to-video demonstrate superior prompt adherence and motion quality compared to competitors. Available through ByteDance platforms (Doubao, Jimeng) and third-party APIs (Pollo AI, Volcano Engine), Seedance is best suited for professional content creators requiring multi-shot narratives and branded commercial content.
Hailuo AI (MiniMax, Shanghai) has gained viral popularity for its physics-based AI video generation and social media content creation capabilities. The Hailuo-02 model, released in June 2025, distinguishes itself through its sophisticated physics engine that simulates realistic interactions including water dynamics, collisions, and gravity. The platform's T2V-01-Director model offers natural language camera control, allowing creators to describe desired camera movements in plain English. Hailuo excels in generating 720p-1080p videos of 6-10 seconds in approximately 3-5 minutes, making it ideal for rapid content production. Key features include character consistency through its S2V-01 model (maintaining facial features, hair, and attire across shots), automated lip-sync for avatar videos, and integrated prompt engineering with FocalML and DeepSeek. With a generous free tier offering 500 credits for new users and paid plans starting at $14.99/month, Hailuo has achieved over $10M ARR and ranks 12th globally in user traffic. The platform has become particularly popular on TikTok and Instagram for creating viral short-form content, earning it the nickname "the viral video generator."
Kling AI (Kuaishou) sets itself apart in the AI video generation space through its exceptional duration and resolution capabilities. Kling 2.1, the latest version, supports video generation up to 2 minutes—significantly longer than most competitors' 10-16 second limits—making it invaluable for explainer videos, product demonstrations, and longer-form content. The platform offers up to 4K resolution on premium tiers with 30 FPS output, surpassing the typical 24 FPS standard of competitors. While it requires more prompt engineering for multi-shot support compared to Seedance, Kling excels in projects requiring extended duration and high-resolution output. The platform supports multiple aspect ratios (16:9, 9:16, 1:1) and provides consistent quality across its generation range, though it does not include native audio generation. Kling AI is best suited for professional content creators needing longer video clips, high-resolution marketing material, and projects where higher frame rates enhance the viewing experience.
D-ID specializes in creating highly realistic talking avatar videos with sophisticated emotion simulation capabilities. The platform stands out for its advanced facial animation technology that creates lifelike expressions and movements. Its ability to generate videos in multiple languages while maintaining lip-sync accuracy makes it valuable for global communication. The platform's custom avatar creation feature allows businesses to maintain brand consistency while leveraging the power of AI-generated video content.
Runway represents the cutting edge of AI-powered video editing and generation. The platform combines traditional video editing capabilities with advanced AI features like automatic background removal, motion tracking, and special effects generation. Its strength lies in its ability to automate complex video editing tasks while maintaining professional quality. The platform's innovative features include text-to-video generation and sophisticated motion synthesis capabilities, making it particularly valuable for creative professionals and content creators.
InVideo transforms video creation through its extensive template-based approach combined with AI capabilities. The platform excels in creating professional-quality videos for marketing, social media, and business presentations without requiring extensive video editing expertise. Its comprehensive media library, including millions of stock assets, combined with automatic text-to-speech capabilities and brand customization options, makes it possible to create consistent, high-quality video content at scale. The platform's strength lies in its balance of automation and customization, allowing users to maintain creative control while benefiting from AI-powered efficiencies.
Luma AI represents a breakthrough in neural rendering and 3D content creation, offering capabilities that extend far beyond traditional video tools. The platform's flagship feature is its ability to create photorealistic 3D models from regular photos or videos, utilizing advanced neural rendering technology. Luma excels in generating 3D assets with exceptional detail and accuracy, making it invaluable for e-commerce, virtual production, and augmented reality applications. Its Gaussian Splatting technology has revolutionized the way 3D scenes are captured and rendered, offering unprecedented speed and quality. The platform's ability to create instant 3D captures from mobile devices has made high-quality 3D content creation accessible to creators without specialized equipment. Particularly noteworthy is Luma's capacity to handle complex materials and lighting, producing results that maintain photorealism while allowing for dynamic manipulation and integration into various production workflows.
Dreamina offers a unique approach to AI video generation, specializing in transforming still images into dynamic, moving content. The platform's technology brings static images to life through sophisticated motion synthesis, creating subtle yet engaging animations that maintain the original image's integrity. What sets Dreamina apart is its ability to understand and animate different elements within an image naturally, from flowing water and moving clouds to subtle facial expressions and body movements. The platform excels in creating atmospheric and emotionally resonant content, making it particularly valuable for artistic projects, social media content, and digital advertising. Its user-friendly interface masks the complex AI technology working behind the scenes, allowing creators to focus on their creative vision rather than technical details.
6.1.4 Avatar Generation
AI Avatar Platforms:
Synthesia has established itself as a leader in AI-powered video creation, particularly excelling in business communication and educational content. The platform's strength lies in its ability to generate professional-quality videos featuring AI avatars that deliver natural-looking presentations in multiple languages. Its enterprise-grade features include custom avatar creation, voice cloning capabilities, and extensive template libraries for various business scenarios. The platform's ability to maintain consistent quality while significantly reducing production time and costs has made it particularly valuable for corporate training, marketing, and educational content. Synthesia's avatars demonstrate sophisticated lip-sync accuracy and natural gestures, creating engaging video content that resonates with audiences across global markets.
HeyGen has revolutionized AI avatar video creation with its comprehensive platform that transforms text, images, or video into talking avatar presentations. Launched in 2020, HeyGen now offers the most advanced avatar technology with Avatar IV, which can turn a single photo—whether of humans, pets, or even fictional characters—into lifelike talking avatars with natural voice sync, expressive facial dynamics, and authentic hand gestures. The platform's video avatar feature allows users to film themselves once and generate unlimited videos without ever being on camera again, creating true digital twins. With over 500 pre-made avatars in its library and 400+ customizable looks, HeyGen supports 175+ languages and 100+ AI voices, making it invaluable for global content creation. The platform's interactive avatars represent cutting-edge innovation, enabling real-time conversational AI that responds to questions with speech, gestures, and facial expressions—perfect for 24/7 customer service, sales, and virtual events. HeyGen's Avatar 3.0 technology understands script context to adjust tone, expressions, and body language dynamically, even handling singing capabilities from soft melodies to fast rap. Available through flexible pricing from free plans (3 videos/month) to enterprise solutions with 4K export and API integration, HeyGen serves marketers, educators, sales teams, and content creators worldwide.
Convai specializes in creating intelligent, conversational AI avatars designed for interactive experiences. The platform focuses on building avatars that can engage in natural dialogue, understand context, and respond dynamically to user interactions. Convai's strength lies in its ability to create avatars that don't just speak but truly converse, making decisions based on conversational flow and maintaining contextual awareness throughout interactions. This makes it particularly valuable for applications requiring sophisticated AI-human interaction, such as virtual assistants, customer service representatives, and interactive gaming characters. The platform's integration capabilities allow developers to embed these conversational avatars into various applications, from websites to virtual reality environments, creating immersive and engaging user experiences that go beyond simple scripted responses.
6.1.5 Virtual World Generation
3D World Models:
World Labs (founded by AI pioneer Fei-Fei Li, the "godmother of AI" and creator of ImageNet) represents a paradigm shift in how AI generates and interacts with 3D virtual worlds. Unlike traditional 2D image or video generation, World Labs builds "Large World Models" with spatial intelligence—AI systems that perceive, generate, and interact with 3D environments as coherent, physically consistent spaces. The platform's groundbreaking technology takes a single image or text prompt and generates interactive, explorable 3D scenes that users can navigate in real-time through a browser. The Marble model (September 2025) showcases the platform's latest capabilities: generating persistent, navigable 3D worlds with bigger environments, superior geometry, and diverse artistic styles. What sets World Labs apart is its RTFM (Read The Field Model) technology, which achieves real-time inference at interactive frame rates on a single NVIDIA H100 GPU while maintaining persistent memory for long-term scene continuity. The AI doesn't just predict pixels—it "imagines" what exists beyond the frame, creating complete rooms, objects, and spaces with object permanence and physics consistency. This means objects remain solid, follow gravity, and don't morph unnaturally between viewpoints.
World Labs' applications span multiple industries: gaming companies can generate expansive 3D worlds without years of development time or massive budgets; film and VFX studios can stage characters in AI-generated environments with controllable camera movements; architects can rapidly prototype spatial layouts; and robotics researchers can train embodied AI agents in simulated worlds with realistic physics. The platform supports dynamic lighting adjustments, reflections, shadows, specular highlights, and game-engine-level realism, all controlled through natural language or visual inputs. With $230M in funding from investors including Andreessen Horowitz, Intel Capital, and Eric Schmidt, and achieving unicorn status (valued over $1 billion), World Labs is positioning itself as the leader in democratizing 3D world creation. The company's vision aligns with Fei-Fei Li's broader mission of developing AI with spatial intelligence—systems that understand the three-dimensional physical world as humans do—representing the next frontier beyond today's text and image-focused AI. Beta access to the Marble model is available through worldlabs.ai, with the first commercial product expected in late 2025.
6.1.6 Audio Generation
Voice Synthesis:
ElevenLabs stands at the forefront of AI voice technology, offering unprecedented quality in voice synthesis and cloning. The platform's sophisticated deep learning models create extraordinarily natural-sounding voices that capture subtle nuances of human speech, including emotion and emphasis. Its multilingual capabilities extend beyond simple translation to maintain authentic pronunciation and cultural accuracy. The platform's API infrastructure allows seamless integration into various applications, making it valuable for audiobook production, gaming, and corporate communications. The voice customization features enable users to create and maintain consistent voice identities across multiple projects.
Murf.ai has established itself as a comprehensive solution for professional voiceover production. The platform combines high-quality voice synthesis with an intuitive interface designed for business users. Its extensive voice library includes a wide range of accents and styles, all maintaining studio-quality output suitable for commercial use. The platform excels in maintaining consistent voice quality across long-form content, making it particularly valuable for e-learning, corporate training, and marketing materials. Its collaborative features and project management tools make it ideal for teams working on large-scale audio content production.
Music and Sound:
Soundraw has transformed music creation through its AI-powered composition engine. The platform excels in generating original, royalty-free music that adapts to specific moods, genres, and project requirements. Its intuitive interface allows users to specify detailed parameters including tempo, intensity, and emotional quality, ensuring the generated music perfectly matches the intended atmosphere. The platform's strength lies in its ability to create professional-quality compositions that sound authentically human while maintaining complete originality and commercial usage rights.
Amper Music provides a sophisticated approach to AI music composition focused on professional applications. The platform stands out for its ability to create complex musical arrangements that adapt to specific brand identities and creative requirements. Its powerful engine allows for detailed customization of musical elements while maintaining professional production standards. The platform's enterprise features include advanced project management tools and comprehensive licensing options, making it particularly valuable for large-scale content production and brand sound identity development.
Suno AI represents a groundbreaking advancement in AI music generation, setting itself apart through its remarkable ability to create complete songs with both instrumental compositions and convincing vocal performances. Suno stands out for its ability to generate fully-realized songs from text prompts, complete with vocals that demonstrate impressive clarity and emotional resonance. The platform can create music across diverse genres, from pop and rock to electronic and classical, while maintaining musical coherence and professional production quality. What makes Suno particularly revolutionary is its capacity to generate believable vocal performances with comprehensible lyrics that align with user prompts, addressing one of the most challenging aspects of AI music generation.
6.2 Professional support
6.2.1 Meeting Assistants:
Otter.ai has revolutionized meeting documentation through its sophisticated AI-powered transcription and analysis capabilities. The platform excels in real-time transcription of multiple speakers, automatically identifying different voices and generating accurate speaker-labeled transcripts. Its advanced features include automated summary generation, keyword extraction, and custom vocabulary learning for industry-specific terminology. The platform's collaborative features enable team members to highlight, comment, and share important moments, while its integration with major video conferencing platforms creates a seamless workflow. Particularly impressive is its ability to generate action items and key insights from conversations, making it invaluable for business professionals who need to capture and act on meeting content effectively.
Fireflies.ai transforms meeting documentation through its comprehensive AI meeting assistant capabilities. The platform distinguishes itself with its ability to not only transcribe but deeply analyze conversation content, extracting actionable insights and maintaining a searchable knowledge base of all meeting content. Its sophisticated AI can identify discussion topics, track action items, and generate detailed meeting summaries automatically. The platform's strength lies in its integration capabilities, working seamlessly with major CRM systems and project management tools to ensure meeting insights flow directly into existing workflow systems. The AI's ability to understand context and maintain conversation threads across multiple meetings makes it particularly valuable for teams managing complex, ongoing projects.
6.2.2 Project Management Aids:
Motion represents a significant advancement in AI-powered project management and scheduling. The platform's distinctive approach combines traditional project management capabilities with sophisticated AI that actively learns from user behavior and team patterns to optimize workflow and time allocation. Its intelligent scheduling system goes beyond simple calendar management, considering factors like energy levels, task complexity, and team availability to create optimal work schedules. The platform excels in automatically adjusting project timelines based on real-time progress and changing priorities, while its predictive analytics help identify potential bottlenecks before they impact project delivery. Motion's strength lies in its ability to create realistic, adaptive schedules that account for the complexities of modern work environments.
Notion AI has transformed collaborative workspace management by integrating powerful AI capabilities into its flexible document and project management platform. The system excels in understanding context across different types of content, from project documentation to team wikis, providing intelligent suggestions and automations that enhance productivity. Its AI capabilities extend beyond simple automation to include sophisticated content generation, automated summarization, and intelligent organization of information. The platform's strength lies in its ability to maintain context across different types of content while providing AI-powered insights that help teams work more effectively. Particularly noteworthy is its ability to learn from team interactions and automatically organize information in ways that enhance accessibility and usefulness.
Monday.ai has revolutionized project management through its integration of sophisticated AI capabilities with visual workflow management. The platform's AI engine excels in predicting project bottlenecks, suggesting resource allocation improvements, and automating routine task management. Its strength lies in combining intuitive visual project tracking with intelligent automation and predictive analytics, making complex project management accessible to teams of all sizes.
ClickUp AI represents a comprehensive approach to AI-powered project management, offering sophisticated automation and intelligence across all aspects of work management. The platform's AI capabilities extend from smart task creation and prioritization to automated documentation and workflow optimization. Its strength lies in its ability to learn from team patterns and automatically suggest improvements to processes while maintaining flexibility across different project management methodologies.
Asana AI enhances project coordination through intelligent workflow automation and predictive task management. The platform excels in understanding project dependencies and automatically adjusting workflows based on team capacity and priorities. Its AI capabilities include sophisticated resource allocation suggestions, automated progress tracking, and intelligent deadline management. The platform's strength lies in its ability to maintain project clarity while automatically handling routine coordination tasks.
6.2.3 Email Management Tools:
Reply.io with AI capabilities represents a significant evolution in email communication management, particularly for sales and business development teams. The platform combines sophisticated email automation with AI-powered personalization that can analyze recipient behavior and optimize communication strategies accordingly. Its AI engine excels in generating contextually appropriate email content while maintaining personal touch points that improve engagement rates. The platform's ability to analyze response patterns and automatically adjust sending times and content approaches makes it particularly valuable for large-scale email campaigns. Its integration with CRM systems and other business tools creates a comprehensive communication management ecosystem that significantly enhances team productivity.
Lavender AI transforms email communication through its sophisticated email coaching and optimization capabilities. The platform excels in analyzing email content and providing real-time suggestions for improvement based on recipient psychology and proven communication patterns. Its ability to personalize email content while maintaining consistency with brand voice and communication strategy makes it particularly valuable for sales and marketing teams.
Lemlist combines AI-powered personalization with advanced email automation capabilities. The platform stands out for its ability to create highly personalized email campaigns at scale, using AI to optimize both content and delivery timing. Its unique approach to personalization includes image and video customization, while its AI engine continuously optimizes campaign performance based on recipient engagement patterns.
Mixmax AI enhances email productivity through intelligent automation and engagement tracking. The platform excels in providing contextual suggestions for email content while automating follow-ups based on recipient behavior. Its integration with CRM systems and ability to maintain consistent communication patterns across team members makes it particularly valuable for sales and business development teams.
6.2.4 Legal Document Analysis:
Harvey AI has emerged as a powerful force in legal technology, offering sophisticated AI-powered document analysis specifically tailored for legal professionals. The platform excels in understanding complex legal language and structures, providing detailed analysis of contracts, cases, and legal documents with remarkable accuracy. Its ability to identify potential issues, inconsistencies, and risk factors while maintaining context across different types of legal documents makes it invaluable for law firms and legal departments. The platform's strength lies in its deep understanding of legal precedent and its ability to connect relevant cases and statutes to current analysis, significantly reducing research time while improving accuracy.
CoCounsel represents a breakthrough in AI-assisted legal work, offering specialized capabilities for contract review and legal research. The platform distinguishes itself through its ability to understand nuanced legal concepts and apply them accurately across different types of legal documents. Its sophisticated analysis capabilities extend beyond simple pattern matching to include understanding of legal principles and their practical applications. The platform excels in identifying potential risks and opportunities in legal documents while maintaining strict compliance with legal standards and requirements. Particularly noteworthy is its ability to learn from user interactions and maintain consistency across different types of legal analysis, making it an invaluable tool for legal professionals handling complex document reviews.
LexCheck represents a breakthrough in contract analysis and negotiation support. The platform excels in identifying potential risks and suggesting improvements in contract language based on established legal standards and best practices. Its ability to maintain consistency across different types of agreements while providing detailed compliance analysis makes it particularly valuable for legal departments handling high volumes of contracts.
6.3 Research and analysis
6.3.1 Literature Review Tools
Elicit represents a breakthrough in AI-powered research assistance, transforming how researchers approach literature reviews and academic research. The platform excels in understanding complex research questions and finding relevant academic papers across multiple disciplines. Its sophisticated natural language processing capabilities can extract key findings, methodologies, and conclusions from papers, presenting them in an easily digestible format. The platform's strength lies in its ability to identify connections between papers and highlight potential research gaps. Particularly impressive is its capacity to generate research insights by synthesizing findings across multiple papers, while maintaining rigorous academic standards in source selection and citation.
Semantic Scholar has revolutionized academic search through its AI-powered approach to understanding research content. The platform distinguishes itself through its ability to analyze the semantic meaning of research papers, going beyond simple keyword matching to understand concepts and relationships between studies. Its advanced features include citation analysis that identifies the most influential papers in a field, while its AI can track the evolution of scientific concepts across time. The platform excels in providing visual representations of research networks and identifying emerging research trends. Its ability to understand the impact and influence of papers makes it particularly valuable for researchers trying to identify seminal works in their field.
Connected Papers offers an innovative approach to literature discovery through its visual graph-based interface. The platform excels in creating interactive visualizations of academic paper relationships, helping researchers understand how different works connect and influence each other. Its sophisticated algorithm considers both citation relationships and semantic similarity, providing insights into research lineage and evolution that might not be apparent through traditional search methods.
NotebookLM represents a significant advancement in AI-powered research analysis and note-taking. The platform, developed by Google, distinguishes itself through its ability to understand and interact with research materials in a conversational manner while maintaining source accuracy and citation integrity. Its sophisticated AI can process and analyze lengthy documents, research papers, and other materials, allowing researchers to engage in natural language conversations about their content. The platform's strength lies in several key areas:
- Contextual Understanding: The AI maintains context throughout conversations about source materials, ensuring accurate and relevant responses while preserving the original meaning of texts.
- Source Grounding: All insights and responses are directly tied to source materials, allowing researchers to easily verify information and trace conclusions back to original texts.
- Interactive Note-Taking: The platform enables dynamic note-taking that combines user insights with AI-generated analysis, creating a collaborative research environment.
- Memory Retention: Unlike traditional chatbots, NotebookLM maintains consistent understanding of previous conversations and documents within a project, allowing for more coherent and progressive research development.
- Citation Accuracy: The system excels in maintaining precise attribution and citation of sources, making it particularly valuable for academic research and scholarly work.
What sets NotebookLM apart is its ability to produce podcast summary which resembles a real conversation. This allows you to listen to your customized podcast while doing other things.
6.3.2 Data Analysis Assistants:
Obviously AI democratizes data analysis through its no-code AI platform that makes sophisticated analysis accessible to non-technical users. The platform excels in automating complex analytical tasks, from predictive modeling to pattern recognition, while maintaining high standards of accuracy. Its intuitive interface masks powerful machine learning capabilities that can handle various types of data analysis, from customer behavior prediction to operational optimization. The platform's strength lies in its ability to generate actionable insights from complex datasets without requiring extensive technical expertise.
MindsDB transforms data analysis through its integration of machine learning capabilities directly into databases. The platform excels in making predictive analytics accessible through SQL queries, allowing organizations to leverage AI capabilities within their existing data infrastructure. Its sophisticated AutoML capabilities can automatically select and optimize machine learning models for specific use cases, while its integration capabilities make it particularly valuable for organizations looking to embed AI capabilities into their applications.
RapidMiner AI accelerates data analysis through its comprehensive machine learning and analytics platform. The platform stands out for its ability to handle complex data preparation, model building, and deployment processes while maintaining accessibility for users with varying levels of technical expertise. Its visual workflow designer and automated model optimization capabilities make sophisticated data analysis more accessible to broader audiences.
H2O.ai provides enterprise-grade AI capabilities through its automated machine learning platform. The platform excels in handling complex data analysis tasks across various domains, from financial modeling to scientific research. Its sophisticated AutoML capabilities can automatically optimize model selection and hyperparameters while providing detailed explanations of model decisions, making it particularly valuable for organizations requiring both power and transparency in their analytics.
6.3.3 Market Research Tools
Semrush AI has transformed digital market research through its comprehensive AI-powered analysis capabilities. The platform excels in providing deep insights into market trends, competitor strategies, and consumer behavior patterns. Its sophisticated AI can analyze vast amounts of market data to identify opportunities and potential threats while providing actionable recommendations. The platform's strength lies in its ability to combine multiple data sources to create comprehensive market intelligence, making it invaluable for strategic planning and competitive analysis.
Surfer SEO revolutionizes content optimization through its AI-powered analysis of search engine ranking factors. The platform distinguishes itself through its ability to provide detailed, data-driven recommendations for content optimization while maintaining natural writing quality. Its sophisticated analysis capabilities extend beyond traditional SEO metrics to include user intent analysis and content structure optimization. The platform's strength lies in its ability to combine multiple ranking factors into actionable content strategies.
Ahrefs AI represents advanced market intelligence through its comprehensive SEO and market research capabilities. The platform excels in analyzing competitor strategies, identifying market opportunities, and tracking industry trends through its sophisticated AI engine. Its ability to process vast amounts of data while providing actionable insights makes it particularly valuable for digital marketers and business strategists.
SparkToro innovates audience research through its AI-powered social listening and audience intelligence platform. The platform excels in identifying audience behaviors, preferences, and influential channels across various online platforms. Its unique approach to discovering audience insights through behavioral analysis provides valuable data for market positioning and content strategy development.
Tavily stands out through its specialized AI search capabilities focused on delivering highly relevant, fact-checked information. The platform's advanced filtering and categorization system ensures users receive precisely targeted results for their queries. Tavily's specialized search modes cater to different types of research, adapting the search methodology based on user needs. The platform's real-time verification and cross-referencing capabilities ensure information accuracy and reliability. Tavily particularly excels in academic and professional research, maintaining high standards for information quality and source credibility. The platform's API integration capabilities enable custom applications and workflows, making it highly adaptable to specific organizational needs. Its sophisticated ranking algorithm considers multiple factors including source credibility, content relevance, and information timeliness.
Phind distinguishes itself as a technical search engine optimized for developers and technical professionals. The platform's specialized focus on coding and technical documentation search sets it apart in the developer tools landscape. Its context-aware system provides relevant code examples and explanations, understanding the specific technical requirements of each query. The platform's real-time integration with technical documentation ensures users have access to the most current information and best practices. Phind's problem-solving focused approach helps developers find practical solutions quickly and efficiently. The developer-friendly interface and features create a streamlined experience for technical professionals. The platform's ability to understand technical context and provide relevant programming solutions makes it an essential tool for software development and technical problem-solving.
6.3.4 Search Engines
ChatGPT Search revolutionizes web search through OpenAI's integration of real-time internet access with advanced language understanding. The platform distinguishes itself by combining the reasoning capabilities of GPT-5 with current web data, delivering comprehensive answers that synthesize information from multiple sources. ChatGPT Search excels in understanding complex queries with multiple layers of intent, providing conversational responses that include proper citations and source attribution. The platform's strength lies in its ability to break down complex questions into logical components and search for each element systematically. What sets ChatGPT Search apart is its natural language understanding—users can ask questions as they would to a human expert, without needing to craft precise search keywords. The platform maintains context across follow-up questions, allowing for iterative refinement of search results. It particularly shines in research scenarios requiring synthesis of information from diverse sources, technical problem-solving, and comparative analysis. ChatGPT Search's integration with OpenAI's broader ecosystem enables seamless transitions between search, analysis, and content creation workflows.
Gemini Search represents Google's cutting-edge integration of its Gemini AI models with real-time web search capabilities. The platform leverages Google's unparalleled search infrastructure combined with advanced multimodal AI understanding to deliver comprehensive, context-aware results. Gemini Search excels in processing queries that span text, images, and data, providing unified responses that draw from Google's vast knowledge base while maintaining current awareness through real-time indexing. The platform's strength lies in its deep integration with Google's ecosystem—seamlessly accessing information from Google Scholar, Google Maps, YouTube, and other services to provide comprehensive answers. What distinguishes Gemini Search is its sophisticated understanding of query intent and context, allowing it to disambiguate complex questions and provide nuanced responses. The platform particularly excels in technical and scientific queries, leveraging Google's extensive academic resources and research databases. Gemini Search's multimodal capabilities enable it to understand and respond to queries involving images, charts, and diagrams, making it invaluable for visual research and data analysis. Its real-time fact-checking and source verification ensure high accuracy in delivered information.
Tavily stands out as a specialized AI search engine purpose-built for researchers, developers, and professionals requiring highly accurate, comprehensive information retrieval. The platform distinguishes itself through its advanced filtering and verification mechanisms that prioritize information quality over speed. Tavily's sophisticated search algorithm employs multiple verification layers, cross-referencing sources and evaluating credibility before presenting results. The platform excels in deep research tasks, offering specialized search modes optimized for academic research, technical documentation, and professional analysis. What sets Tavily apart is its developer-friendly API that enables seamless integration into custom applications and workflows, making it ideal for building AI agents and research automation systems. The platform's real-time crawling capabilities ensure access to the latest information while maintaining strict quality standards. Tavily particularly shines in scenarios requiring high factual accuracy—it actively filters out unreliable sources and prioritizes authoritative, peer-reviewed, and professionally verified content. Its ranking algorithm considers source credibility, content depth, information timeliness, and cross-reference validation, delivering results that meet professional research standards. The platform's ability to handle complex, multi-faceted queries while maintaining accuracy makes it indispensable for serious research applications and enterprise knowledge systems.
You.com represents a new generation of AI-powered search that combines traditional web search with conversational AI capabilities. The platform distinguishes itself by providing contextual, multi-format results while maintaining transparency in source attribution. At its core, You.com excels in real-time information synthesis, pulling data from multiple sources while maintaining accuracy and relevance. The platform's code-specific search capabilities make it particularly valuable for developers, offering integrated AI assistance for technical queries. The multi-modal search functionality incorporates text, images, and code seamlessly, creating a comprehensive search experience. Users benefit from customizable search experiences through specialized apps and integrations, while the platform maintains a strong focus on privacy with transparent result sourcing. What sets You.com apart is its ability to balance traditional search functionality with AI-powered insights, making it an invaluable tool for both general users and technical professionals.
Perplexity AI transforms information discovery through its sophisticated AI-driven search and synthesis capabilities. The platform excels in providing real-time information processing with built-in fact-checking mechanisms that ensure accuracy and reliability. Its conversational search interface maintains context throughout user interactions, creating a more natural and intuitive search experience. The platform's comprehensive source citation and verification system ensures transparency and trustworthiness in all results. Perplexity particularly shines in academic and professional research support, offering detailed insights while maintaining rigorous standards for information accuracy. The platform's integration of current events and latest information ensures users have access to up-to-date knowledge. Its unique approach combines the comprehensive nature of traditional search engines with the intuitive interaction of AI assistants, delivering detailed, cited responses to complex queries while maintaining conversation context.
6.4 Technical assistance
6.4.1 Code Generation
GitHub Copilot transforms software development through its sophisticated AI pair programming capabilities. The platform excels in understanding complex development contexts and generating contextually appropriate code suggestions. Its deep learning model, trained on vast repositories of public code, demonstrates remarkable accuracy in predicting appropriate code patterns and implementations. The platform stands out in its ability to understand natural language descriptions and convert them into functional code across numerous programming languages. Copilot's real-time suggestions adapt to individual coding styles and project requirements, while maintaining consistency with established patterns. The system excels particularly in handling boilerplate code, common programming patterns, and complex algorithmic implementations, significantly accelerating development workflows.
Windsurf represents an emerging force in AI-powered development assistance, offering sophisticated code completion and generation capabilities across multiple IDEs and languages. The platform emphasizes speed and accuracy in its suggestions while maintaining compatibility with various development environments. Its approach to context understanding and code generation focuses on practical, production-ready code suggestions. The platform excels in understanding project-specific patterns and maintaining consistency across large codebases.
Cursor represents a significant advancement in AI-powered code editing and generation, distinguishing itself through its integrated development environment specifically designed for AI interaction. The platform transforms the coding experience by combining sophisticated code generation with intelligent code editing and refactoring capabilities. Its chat-based interface enables natural language interaction for complex coding tasks, allowing developers to describe features or modifications in plain English and receive contextually appropriate implementations. Cursor excels in several key areas: What sets Cursor apart is its ability to understand entire codebases and maintain context across files and functions. The platform's real-time editing capabilities extend beyond simple code completion to include intelligent refactoring, bug fixing, and code explanation. Its sophisticated AI can handle complex tasks such as:
- Architecture Planning: The platform can assist in designing system architectures and suggesting implementation approaches for complex features.
- Code Transformation: Intelligent assistance in converting code between languages, updating deprecated APIs, and modernizing legacy code.
- Context-Aware Editing: Understanding of the entire project structure, allowing for more accurate and relevant code suggestions across multiple files.
- Documentation Generation: Automatic generation of comprehensive documentation and code comments that maintain consistency with existing documentation styles.
- Test Generation: Creation of unit tests and test cases based on existing code implementation and functionality requirements.
The platform's strength lies in its ability to serve as both an intelligent code editor and an AI programming assistant, providing immediate feedback and suggestions while maintaining code quality and consistency. Its unique approach to combining traditional IDE features with AI capabilities creates a seamless development experience that accelerates coding workflows while reducing cognitive load on developers.
Replit has evolved into a collaborative, browser-based IDE with powerful AI features, including code generation, completion, and debugging assistance. Its "Ghostwriter" AI helps with explaining, transforming, and generating code, aiming to streamline the entire development lifecycle within a single platform.
Lovable (LovableDev) is an AI-powered platform focused on generating high-quality, human-like documentation for code. It analyzes codebases and produces comprehensive documentation, including API references and explanations, aiming to keep documentation up-to-date with minimal developer effort.
6.4.2 Debugging Assistants
Tabnine revolutionizes code completion and debugging through its AI-powered full-line and full-function completion capabilities. The platform learns from both public code repositories and developers' private code, creating highly personalized and context-aware suggestions. Its debugging capabilities extend beyond simple error detection to understanding potential logic issues and performance optimizations. The platform's strength lies in its ability to predict and suggest complex code patterns while identifying potential issues before they manifest in runtime.
DeepCode transforms bug detection through its sophisticated static analysis capabilities enhanced by AI. The platform excels in identifying complex code issues, security vulnerabilities, and performance bottlenecks through semantic analysis. Its unique approach combines traditional static analysis with machine learning to understand code context and potential issues. The platform particularly shines in its ability to suggest fixes and improvements while explaining the reasoning behind its recommendations.
CodeGuru advances code review and performance optimization through its machine learning-powered analysis capabilities. The platform specializes in identifying resource leaks, performance bottlenecks, and potential security issues in production code. Its sophisticated analysis capabilities extend to runtime behavior prediction and optimization suggestions. The platform's strength lies in combining static analysis with runtime intelligence to provide comprehensive code improvement recommendations.
Google Jules is an async development agent. Jules tackles bugs, small feature requests, and other software engineering tasks, with direct export to GitHub.
6.4.3 Infrastructure Management
HashiCorp transforms infrastructure management through its suite of AI-enhanced tools for cloud infrastructure orchestration. The platform excels in automating complex infrastructure deployments while maintaining security and compliance requirements. Its AI capabilities extend to predicting resource needs, optimizing configurations, and identifying potential infrastructure issues before they impact production. The platform's strength lies in its ability to handle complex multi-cloud environments while maintaining consistency and security.
PagerDuty with AI advances incident management through intelligent automation and predictive analysis. The platform transforms traditional incident response through AI-powered event correlation and intelligent routing capabilities. Its machine learning models excel in identifying patterns in system behavior and predicting potential incidents before they occur. The platform's strength lies in reducing alert fatigue while ensuring critical issues receive immediate attention through sophisticated prioritization algorithms.
Pulumi IQ represents advancement in infrastructure as code through its AI-powered assistance capabilities. The platform excels in providing intelligent suggestions for infrastructure configurations and optimizations across multiple cloud providers. Its sophisticated analysis capabilities help identify potential security risks and compliance issues in infrastructure code. The platform's strength lies in combining traditional infrastructure as code with AI-powered insights and recommendations.
6.4.4 API Documentation
Theneo transforms API documentation through its AI-powered documentation generation and maintenance capabilities. The platform excels in automatically generating comprehensive API documentation from code while maintaining accuracy and clarity. Its sophisticated natural language processing capabilities ensure documentation remains accessible to both technical and non-technical audiences. The platform's strength lies in its ability to keep documentation synchronized with code changes while maintaining consistent style and terminology.
ReadMe AI advances API documentation through intelligent content generation and user experience optimization. The platform excels in creating interactive API documentation that adapts to user behavior and preferences. Its AI capabilities extend to generating example code, predicting common use cases, and optimizing documentation structure for maximum clarity. The platform's strength lies in its ability to maintain comprehensive documentation while ensuring it remains accessible and practical for developers of varying skill levels.
Swagger AI enhances API documentation through automated OpenAPI specification generation and maintenance. The platform excels in understanding API structures and generating accurate, detailed specifications. Its AI capabilities help identify potential issues in API design and suggest improvements for better developer experience. The platform's strength lies in maintaining consistency between implementation and documentation while ensuring specifications remain current and accurate.
Chapter 7: The Five A's of Applied GenAI at Work
The integration of Generative AI into the workplace is moving beyond simple experimentation and evolving into a structured toolkit for applied innovation. This transformation is not monolithic; rather, it represents a spectrum of capabilities that range from direct interaction with foundational models to the deployment of fully autonomous systems. Understanding this spectrum is crucial for professionals and organizations aiming to harness AI for tangible gains in efficiency, problem-solving, and value creation.
This chapter reframes the landscape of modern AI tools through the lens of The Five A's of Applied GenAI:
- Access (The Foundation): Interacting directly with raw, general-purpose foundation models.
- Assistants (The Domain Expert): Creating customized, knowledge-aware chatbots for specific domains.
- Application (The Niche Creator): Building task-specific, single-purpose applications for niche problems.
- Automation (The Workflow Engine): Connecting disparate apps and services to automate repetitive, multi-step tasks.
- Agents (The Autonomous Actor): Deploying systems that can independently plan, reason, and execute complex, multi-step goals.
This framework provides a clear progression, moving from high human-in-the-loop interaction (Access) to high-level human supervision (Agents), empowering workers to select the right tool (or combination of tools) for the task at hand.
7.1 Access: The Foundation Models
The bedrock of the modern generative AI revolution is Access to foundational models. These are the large-scale, general-purpose models (LLMs) trained on vast swaths of internet data, capable of understanding and generating human-like text, code, and other forms of media. Interacting with these models is typically done through a direct conversational interface. This "Access" layer represents the raw material of generative AI.
Key Characteristics:
- General-Purpose: They are designed to be "jacks-of-all-trades," capable of drafting emails, brainstorming ideas, writing code, summarizing articles, and answering general knowledge questions.
- Reactive: They respond to user prompts and have limited memory of past interactions (context window).
- Stateless Knowledge: Their knowledge is "frozen" at the time of their last training run, meaning they are not aware of real-time events or private, proprietary data.
This category includes the most recognizable names in AI, which serve as the engine for many of the other "A's" in this framework. Notable examples include OpenAI's ChatGPT (powered by GPT), Google's Gemini (Advanced, Pro, and Ultra), Anthropic's Claude (Sonnet, Opus, Haiku), Grok (xAI's model), and Deepseek (a family of models, including specialized coder models).
While powerful, using these models directly for specialized work can be inefficient. A professional must constantly provide context, copy-paste information, and manually verify facts against private data sources, which leads us to the next layers of application.
7.2 Assistants: Building Domain-Specific Chatbots
The "Assistant" layer addresses the primary limitation of the "Access" layer: the lack of domain-specific knowledge. A foundational model knows about the world, but it doesn't know about your company, your projects, or your internal documentation. An AI Assistant is a customized chatbot built with domain knowledge, typically achieved by connecting a foundation model to one or more knowledge sources through Retrieval-Augmented Generation (RAG).
Instead of just chatting with a general-purpose AI, you are now conversing with an expert that has read all your team's documents, understands your product specs, or is trained on your specific area of research.
Key Characteristics:
- Domain-Specific: Grounded in a specific body of knowledge (e.g., project documents, codebases, academic papers, product manuals).
- Knowledge-Aware: Can cite sources, answer questions based on private data, and synthesize information from its specific knowledge base.
- Persistent & Focused: Designed to be a long-term "colleague" for a specific role or function.
Platforms and Examples: Customized GPTs (OpenAI) allow users to build their own GPT by providing natural language instructions and uploading knowledge files. Coze and Poe Bot Builder provide user-friendly interfaces to build sophisticated chatbots. GAIforResearch.com's "Mimi" acts as an intelligent matchmaker for researchers. Notion AI is deeply integrated into users' Notion workspaces, and Microsoft's Copilot (Enterprise) can reason over organizational emails, chats, meetings, and documents.
These assistants augment human capabilities by providing instant, contextual, and expert-level support within a specific domain, dramatically reducing the time spent searching for information.
7.3 Application: Creating Niche, Task-Specific Tools
The "Application" layer represents the next step in harnessing AI for specific, practical problems. This is about moving from a general-purpose "chat" to a single-purpose "tool." The key insight here is the ability for any user (not just a developer) to create a micro-application to solve a niche problem for which no commercial app exists.
This layer is defined by the new wave of AI app creators. These platforms allow users to build and share simple, focused tools, often with just a natural language prompt. For example, a user might face the niche problem of converting a text-based meeting agenda into calendar invitation files. Instead of waiting for a major software vendor to add this feature, they can use an app creator like Google AI Studio to build "Catlendar," a simple web app that takes text as input and produces calendar files as output. Visit https://catlendar.gaiforresearch.com to try it out.
Key Characteristics:
- Single-Purpose: Designed to do one thing well.
- No-Code/Low-Code: Built using natural language prompts, simple forms, or visual interfaces.
- Solves Niche Problems: Fills the "long tail" of software needs that are too specific for large-scale app development.
Platforms Enabling This Layer: Google AI Studio, Lovable, Poe App Creator, and Replit are increasingly used with AI SDKs to quickly build and host niche web applications. This "Application" layer empowers employees to become "citizen AI developers," creating a personalized toolkit to solve their unique day-to-day workflow frictions.
7.4 Automation: Automating Repetitive Workflows
The "Automation" layer connects AI to the wider digital ecosystem. While an Assistant provides answers, an Automation platform takes action. These platforms specialize in automating routine, multi-step tasks and workflows that involve multiple applications and services, freeing up human resources from repetitive work to focus on more strategic and creative endeavors.
7.4.1 Key Automation Platforms
Leading platforms include Zapier (no-code with 7,000+ app integrations), Make.com (visual workflow design with conditional logic), n8n (open-source with self-hosting options), and Dify.ai (focused on AI-enhanced workflows with LLM integration). OpenAI Agent Builder represents emerging tools that blend advanced workflow automation with agentic capabilities. Traditional RPA leaders like UiPath and Automation Anywhere continue to evolve by integrating AI models.
7.4.2 Advanced Use-Cases and Complex Automations
Workflow automation enables complex orchestrations such as intelligent document processing (automating invoice processing), adaptive customer service (sentiment-based ticket routing), AI-driven sales outreach (lead research and personalized emails), and automated onboarding (provisioning accounts across multiple systems).
7.4.3 Challenges in Workflow Automation
Deploying effective workflow automation presents challenges including integration complexity, API limits and reliability, security and data privacy concerns, data quality dependencies, and ongoing maintenance and monitoring requirements.
7.4.4 The Evolving Role of AI within Workflow Automation
AI is becoming integral to modern workflow automation through LLMs as workflow engines, AI-driven decision points, intelligent data extraction combining OCR and NLP, and generative AI for content creation. This integration shifts automation from executing predefined instructions to creating intelligent, responsive, and continuously improving processes.
7.5 Agents: Performing Tasks Autonomously
The final "A" is Agents, representing the most advanced paradigm where AI systems can pursue complex goals with significantly less direct human supervision. An Assistant answers questions, an Automation executes predefined workflows, but an Agent achieves high-level goals.
Autonomous agents are designed to understand high-level objectives, break them down into manageable sub-tasks, select and use appropriate tools, interact with their environment, learn from feedback, and adapt their strategy to achieve goals.
A Note on "Agent" Hype: The term "agent" is currently a major source of industry hype. Many products are marketed as "agents" when they are more accurately sophisticated Assistants or Automation workflows. True autonomous agents possess a higher degree of independence in planning and self-correction, which is still an emerging capability.
7.5.1 Characteristics and Examples
Unlike assistants or automation platforms, agents exhibit independence through planning and reasoning, tool use, self-correction, task decomposition, and proactive behavior. Early examples include AutoGPT (experimental open-source agent), OpenAI Agent Mode (planning and executing complex queries), and Deep Research Agents (conducting multi-step research and producing structured reports).
7.5.2 Advanced Agent Platforms (2025 Snapshot)
Flowith distinguishes itself through "Infinite Agent" framework enabling multi-step reasoning across vast contexts. Key innovations include infinite context processing, multi-agent collaboration, and an AI-curated "Knowledge Garden." Use cases include academic research and large-scale content production.
Manus has gained recognition for "fire-and-forget" autonomy in real-world tasks. Core capabilities include asynchronous cloud execution, transparent process visualization, and deep tool ecosystem integration, though it faces stability issues during peak usage.
Skywork Super Agents targets enterprise productivity with specialized AI Office Agents. Architectural breakthroughs include modular agent frameworks for chaining agents into custom pipelines, multi-modal output, and self-optimizing workflows. Industry applications include generating SEC-compliant reports and automating e-commerce analytics.
7.6 The 'A' Continuum: A Comparative Analysis
It is crucial to understand that these Five A's are not always distinct categories; they exist on a continuum of autonomy, complexity, and user control. Many modern solutions blend these paradigms. An "Application" might be built using an "Access" model, an "Assistant" might trigger an "Automation," and a complex "Agent" inherently uses all capabilities.
The key is to understand the primary goal of each layer. The framework moves from raw interaction to creating experts, to building tools, to automating processes, and finally to delegating goals.
Industry Impact and Blended Approaches: Organizations often benefit from hybrid approaches. In customer service, an Assistant handles first-line support, triggers Automations for standard requests, and escalates complex issues to Agents. In healthcare, doctors use Applications for transcription, Assistants for diagnostic support, Automations for billing, and Agents for research. In finance, customers use Assistants for inquiries, loan officers use Automations for processing, and Agents monitor for fraud detection.
7.7 Conclusion
The Five A's (Access, Assistants, Application, Automation, and Agents) provide a comprehensive framework for understanding and applying generative AI in the workplace. This model maps a clear journey from interacting with raw AI (Access) to creating knowledge experts (Assistants), building niche tools (Application), optimizing processes (Automation), and ultimately delegating complex outcomes (Agents).
Understanding these distinctions is crucial for selecting the right tool for the job. The future of work will not be defined by a single AI but by a blend of all five, empowering professionals to optimize their efficiency, augment their capabilities, and unlock new avenues for innovation.
Part III
Strategy, Implementation, and Ethics
How organizations scale, govern, and ethically deploy GenAI
Chapter 8: Generative AI in Key Business Functions
Generative Artificial Intelligence, AI systems capable of creating text, images, designs, and even strategies, is no longer confined to research labs or tech startups. It is being actively adopted across core business functions to drive creativity, efficiency, and innovation. This chapter explores how generative AI adds value in Marketing, Research & Development (R&D), Human Resource Management (HRM), and General Management/Strategy. For each area, we will discuss practical applications, real-world case studies from various industries (consulting, technology, FMCG, etc.), and notable tools or platforms enabling these transformations. The focus is on clear, business-oriented insights rather than technical depth, consistent with our practical tone in earlier chapters.
8.1 The GenAI-Powered Value Chain
Before exploring specific business functions, it is essential to understand how Generative AI transforms the entire organizational value chain. Drawing from Michael Porter's classic value chain framework, we can visualize how AI integrates across both primary activities (those directly involved in creating and delivering products/services) and support activities (those enabling and enhancing the primary functions).
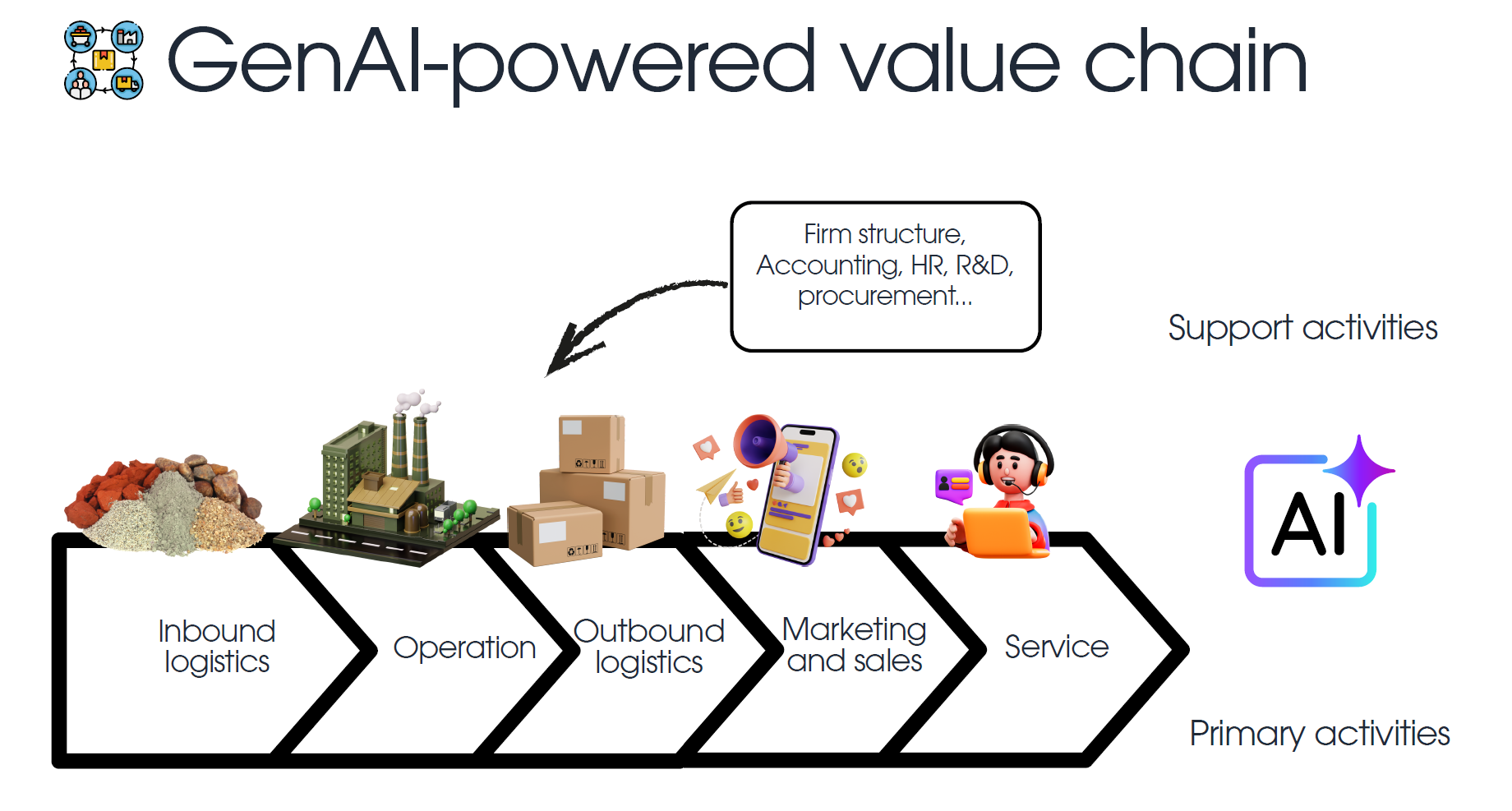
Figure 8.1: The GenAI-Powered Value Chain
This framework demonstrates how AI acts as a horizontal enabler across the entire business ecosystem—from raw material sourcing to customer service—while simultaneously supporting foundational functions like HR, R&D, and accounting. Understanding this comprehensive integration is critical for developing a holistic AI strategy rather than treating AI as isolated point solutions.
Primary Activities: AI Across the Operational Core
1. Inbound Logistics: Intelligent Supply Chain Management
Generative AI transforms how organizations manage incoming materials and information:
- Demand Forecasting: A global electronics manufacturer uses AI to analyze historical sales data, social media trends, and economic indicators to predict component demand with 95% accuracy, reducing inventory costs by 30%.
- Supplier Communication: AI automatically generates and translates purchase orders, quality specifications, and compliance documentation across 40+ languages for international suppliers.
- Quality Inspection: Computer vision models powered by generative AI create synthetic defect images to train inspection systems, identifying manufacturing flaws in real-time at receiving docks.
- Route Optimization: Logistics AI generates optimal shipping routes considering weather, traffic, fuel costs, and delivery deadlines, creating detailed scheduling reports for warehouse managers.
2. Operations: AI-Enhanced Production and Service Delivery
The operational core sees some of the most transformative AI applications:
- Process Optimization: A chemical plant uses AI to generate thousands of virtual simulations testing different temperature, pressure, and catalyst combinations, discovering a new process that increased yield by 12% without physical experimentation.
- Predictive Maintenance: Manufacturing equipment generates maintenance schedules by analyzing sensor data patterns. When anomalies are detected, AI creates detailed maintenance reports with visual diagrams showing likely failure points.
- Quality Control Documentation: AI automatically generates comprehensive quality reports, root cause analyses, and corrective action recommendations from production line data, reducing documentation time from days to minutes.
- Standard Operating Procedures: When processes change, AI generates updated SOPs in multiple formats (text, video, interactive guides) tailored to different worker skill levels and languages.
- Production Planning: AI creates optimized production schedules considering machine capacity, workforce availability, material lead times, and customer deadlines, generating detailed Gantt charts and resource allocation plans.
3. Outbound Logistics: Smart Distribution and Fulfillment
AI revolutionizes how finished products reach customers:
- Warehouse Automation: An e-commerce company uses AI to generate optimal warehouse layouts and picking routes. The system creates visual heat maps showing high-traffic areas and suggests reorganization strategies quarterly.
- Shipment Documentation: AI automatically generates shipping labels, customs declarations, certificates of origin, and compliance documentation for international shipments, reducing processing time by 85%.
- Last-Mile Optimization: Delivery route AI considers package size, delivery windows, traffic patterns, and driver capabilities to create efficient routes, generating turn-by-turn instructions and customer communication templates.
- Returns Processing: When customers initiate returns, AI generates personalized return labels, analyzes return reasons to identify product quality trends, and creates restocking or disposal recommendations.
- Inventory Visibility: AI creates real-time inventory status reports across distribution networks, generating alerts and recommended actions when stock levels trigger replenishment thresholds.
4. Marketing and Sales: Personalization at Scale
Perhaps the most visible transformation occurs in customer-facing activities:
- Content Generation: A consumer goods company uses AI to create 10,000+ product description variations optimized for different demographics, channels (web, mobile, print), and cultural contexts, maintaining brand voice across all variants.
- Campaign Creative: Marketing teams generate hundreds of ad variations (headlines, body copy, visuals, CTAs) for A/B testing across platforms. A financial services firm created 500 unique email campaign variants, discovering that personalized retirement planning language increased conversions by 43%.
- Sales Enablement: AI generates personalized sales presentations, proposal documents, and ROI calculators based on prospect industry, company size, and pain points mentioned in discovery calls.
- Market Research: AI analyzes thousands of customer reviews, social media conversations, and competitor websites to generate comprehensive market intelligence reports, trend analyses, and strategic recommendations.
- Pricing Strategy: Dynamic pricing AI generates recommendations considering competitor prices, inventory levels, seasonal demand, and customer purchase history, creating pricing rationale documents for sales teams.
- Lead Nurturing: AI creates personalized email sequences, follow-up messages, and content recommendations based on prospect behavior, automatically adjusting messaging tone and timing based on engagement patterns.
5. Service: AI-Augmented Customer Support
Post-sale service becomes more efficient and personalized:
- Customer Support Automation: AI chatbots handle 70% of routine inquiries, but when complex issues arise, they generate comprehensive case summaries for human agents including customer history, previous interactions, and suggested resolution paths.
- Troubleshooting Guides: When new product issues emerge, AI automatically generates step-by-step troubleshooting guides with screenshots and videos in multiple languages within hours.
- Warranty Processing: AI reviews warranty claims, generates approval or denial letters with clear explanations, and creates fraud pattern reports identifying suspicious claim clusters.
- Knowledge Base Maintenance: As support tickets are resolved, AI automatically updates knowledge base articles, creates FAQ entries, and generates training materials for support staff.
- Customer Feedback Analysis: AI analyzes support tickets, surveys, and social media mentions to generate monthly customer satisfaction reports with actionable insights and prioritized improvement recommendations.
Support Activities: AI Enabling Organizational Excellence
Firm Infrastructure (Accounting, Finance, Legal, Planning):
- Financial Reporting: AI generates comprehensive financial reports, variance analyses, and executive summaries from raw transaction data, creating visualizations and narrative explanations of key metrics.
- Compliance Documentation: Regulatory compliance AI generates required filings, audit trails, and policy documentation, automatically updating materials when regulations change.
- Strategic Planning: AI assists in scenario planning by generating financial projections under different market conditions, creating detailed strategic planning documents with risk assessments.
- Contract Management: Legal AI reviews contracts for standard clauses, generates redlines, creates summaries of key terms, and flags non-standard provisions for attorney review.
Human Resource Management:
- Recruitment: AI generates job descriptions optimized for different platforms, creates personalized candidate outreach messages, and produces interview question sets tailored to role requirements and company culture.
- Onboarding: New hire AI creates personalized onboarding schedules, generates role-specific training materials, and produces welcome packets customized to department and location.
- Performance Management: AI analyzes performance data to generate review summaries, development plan recommendations, and career path suggestions, helping managers provide more structured feedback.
- Learning & Development: Training AI creates customized learning paths, generates course materials, and produces knowledge assessments based on role requirements and skill gaps.
Research & Development:
- Literature Review: Research AI analyzes thousands of scientific papers to generate comprehensive literature reviews, identifying knowledge gaps and research opportunities.
- Experimental Design: AI generates experimental protocols, creates statistical analysis plans, and produces safety documentation for new research initiatives.
- Patent Research: IP AI conducts patent landscape analyses, generates prior art reports, and creates draft patent applications from invention disclosures.
- Technical Documentation: AI transforms research findings into technical specifications, white papers, and regulatory submission documents.
Procurement:
- Vendor Analysis: Procurement AI generates comprehensive vendor comparison reports analyzing pricing, quality metrics, delivery performance, and risk factors.
- RFP Creation: AI creates detailed Request for Proposal documents, generates evaluation criteria, and produces vendor scorecards.
- Contract Negotiation: AI generates negotiation strategies based on market analysis, creates counteroffer templates, and produces contract comparison documents.
- Spend Analysis: AI analyzes procurement data to generate insights on spending patterns, identifies cost-saving opportunities, and creates strategic sourcing recommendations.
The Integrated Advantage: The true power of the GenAI-powered value chain emerges when these capabilities work in concert. For example, demand forecasts from inbound logistics inform production planning in operations, which guides marketing campaign timing, which shapes service resource allocation. AI doesn't just optimize individual functions—it creates an intelligent, adaptive business ecosystem where insights flow seamlessly across traditional functional boundaries.
8.2 Marketing: Transforming Content and Customer Engagement with AI
Marketing has emerged as one of the earliest and most impactful adopters of generative AI. By automating and augmenting content creation, generative AI enables marketers to produce high-quality advertisements, personalized campaigns, and creative visuals at unprecedented speed and scale. It can draft compelling copy, generate unique images or videos, and tailor messaging to different audiences, all while preserving brand voice and identity. The value proposition is clear: faster content production, lower creative costs, and more engaging, personalized customer experiences.
Generative AI for Content Creation and Campaigns
Brands are using AI to generate marketing content that would traditionally require extensive human creative effort. For example, Microsoft employed generative AI tools to script, storyboard, and produce a video ad for its Surface devices, achieving a 90% reduction in time and cost compared to a conventional production and viewers did not even notice the ad's AI-generated elements. This showcases how AI can accelerate creative workflows without sacrificing quality.
Similarly, Coca-Cola experimented with AI to generate personalized holiday advertisements. The company's marketing team used generative models to produce dozens of ad variations tailored to different U.S. cities and audiences. The result was thousands of digital content pieces created in a fraction of the usual time, though Coca-Cola did face some criticism about the authenticity and quality of a few AI-crafted visuals. Overall, these projects demonstrate that AI can shoulder much of the heavy lifting in content generation, allowing human marketers to focus on strategy and creative direction.
Personalization at Scale
A major promise of AI in marketing is the ability to deliver personalized content and customer experiences at scale. Generative AI can dynamically create product descriptions, emails, or ads tailored to individual consumer segments, something that would be infeasible to do manually for millions of customers. E-commerce giant Alibaba provides a prominent example in Asia: its marketing arm launched an AI copywriting tool that generates product descriptions and ad copy for merchants. This "AI copywriter" can produce up to 20,000 lines of copy per second, helping sellers on Alibaba's platforms quickly create engaging descriptions for their listings. By 2018, thousands of Chinese small businesses were using this tool daily to write product copy, dramatically reducing the time spent on content creation.
In the West, Amazon has similarly used generative AI to enhance customer communications, for instance, by generating concise review summaries for products to help shoppers digest feedback quickly. These applications illustrate how generative AI enables mass personalization: each customer effectively sees content crafted "just for them," whether it's a city-customized Coke ad or a dynamically written product summary, enhancing engagement and conversion rates.
Enhancing Creativity and Branding
Beyond efficiency, generative AI can also expand creative horizons for marketing teams. It can produce novel imagery, designs, and even interactive content that enriches a brand's storytelling. A striking example comes from Heinz, the iconic ketchup brand. Heinz's marketing team used OpenAI's DALL·E 2 image generator to create a series of ketchup bottle visuals in unexpected scenarios, highlighting that even an AI, when asked to draw ketchup, often produces something resembling a Heinz bottle. The AI-generated artwork went viral on social media, reinforcing Heinz's brand recognition in a playful, modern way.
Likewise, luxury and fashion brands are tapping AI for creative campaigns: handbag maker Misela crafted a global marketing campaign by generating images of models carrying its bags in various international locales, without ever sending a photographer on location. Using AI-generated backgrounds and scenes, Misela showcased its products "around the world" virtually, significantly cutting production costs and time while still captivating customers with diverse settings. These examples show that AI is not just a cost-cutter; it can be a creative collaborator that helps brands tell stories in new and engaging forms.
Real-World Case Snapshots
Table 8.1 highlights several real-world applications of generative AI in marketing across different industries and regions, along with their outcomes.
| Company & Campaign | Generative AI Application | Outcome/Impact |
|---|---|---|
| Microsoft – "Surface Ad" (Tech, US) | AI-generated ad script, visuals, and editing | 90% reduction in production time and cost; viewers didn't notice AI content. |
| Coca-Cola – Holiday Ads (FMCG, US) | Personalized AI-generated ad variants for different cities | Thousands of tailored ads created rapidly; improved local engagement (with some quality critiques). |
| Headway (EdTech, Europe) | AI tools (Midjourney, HeyGen) to create video and static ads | 40% increase in ROI on video ads; 3.3 billion impressions in first half of 2024. |
| Nutella (Ferrero, FMCG, Europe) | AI-designed unique packaging – 7 million one-of-a-kind jar labels | All jars sold out in one month, boosting brand visibility and consumer excitement. |
| Nike – Serena Williams Tribute (Sports, US) | AI-generated video merging footage of Serena Williams from different years | High-impact campaign honoring an icon; showcased innovative storytelling, gained significant media attention. |
| Alibaba – AI Copywriter (E-commerce, Asia) | AI-generated product descriptions for online listings | Thousands of merchants create custom copy in seconds; faster listing updates and more consistent quality. |
As shown above, global brands from the US, Europe, and Asia are embracing generative AI to supercharge their marketing. They report faster content cycles, higher ROI on campaigns, and new ways to engage customers. A 2024 marketing industry survey found that 51% of marketers have used or plan to use generative AI, with image generation (69% of marketers) and text generation (58%) being the most common applications. Popular platforms enabling these capabilities include Jasper and Copy.ai for copywriting, Midjourney and Adobe Firefly for image creation, Synthesia and HeyGen for synthetic video ads, and large language models like OpenAI's GPT-4 for generating everything from social media posts to strategy briefs. Marketers should choose tools that fit their brand needs and ensure human oversight (to maintain brand voice and check for accuracy or biases). With thoughtful use, generative AI becomes a powerful co-creator, allowing marketing teams to be more agile, creative, and customer-centric in the fast-paced digital landscape.
8.3 R&D: Accelerating Innovation and Design
Beyond marketing, generative AI is making waves in Research & Development (R&D), the engine of innovation for products and services. R&D spans everything from designing physical products and developing new formulas, to creating software and entertainment content. Generative AI adds value by rapidly generating prototypes, simulating ideas, and optimizing designs far faster than traditional methods. It serves as a creative partner to engineers and scientists, exploring thousands of possibilities (design permutations, molecular structures, code solutions) in a fraction of the time, thereby shortening development cycles and unlocking novel solutions.
Product Design and Engineering
One of the most tangible impacts of generative AI is in product design, often via generative design software that creates optimized geometries under given constraints. A classic example is General Motors (GM), which partnered with Autodesk to redesign a simple but critical part: the seat-belt bracket that anchors seat belts in cars. Using generative design algorithms, GM's engineers input the requirements (attachment points, load forces, allowable materials, etc.), and the software produced over 150 alternative designs, many with organic, complex shapes a human alone might never conceive. The chosen AI-generated design combined what used to be eight separate components into a single 3D-printed part. Remarkably, the new bracket is 40% lighter and 20% stronger than the original design, contributing to vehicle weight reduction (crucial for electric cars' range and efficiency) without sacrificing strength.
In Europe, Airbus applied a similar approach to an interior aircraft component, a partition wall. By leveraging Autodesk's generative design, Airbus created a "bionic partition" with a nature-inspired lattice structure that achieved a 45% weight reduction while maintaining full strength. Lighter airplane parts translate to significant fuel savings and emissions reduction. These cases illustrate how in automotive and aerospace R&D, generative AI is enabling lighter, stronger, and more efficient designs, compressing what used to be months of design iterations into weeks.
Faster Product Development Cycles
Generative AI is also helping companies dramatically speed up the R&D process for new products. In the fast-moving consumer goods (FMCG) sector, PepsiCo provides a striking example. Traditionally, developing a new snack flavor or product variation might take 6–12 months of brainstorming, formulation, and testing. PepsiCo's R&D teams turned to generative AI to accelerate this. By analyzing vast combinations of ingredients, flavors, and consumer taste data, AI can suggest optimal recipes and even novel snack shapes. Using these tools, PepsiCo managed to shrink the development cycle for a new Cheetos snack to just six weeks, a fraction of the usual time.
"Generative AI allows us to optimize product attributes in a way that was previously unimaginable," says Athina Kanioura, PepsiCo's Chief Strategy and Transformation Officer, noting that AI helped reduce the number of test cycles needed for the new Cheetos product. The generative models proposed flavor variations and ingredient mixes that met consumer preferences for taste and texture, which R&D could then quickly prototype. Beyond new products, PepsiCo also uses AI to reformulate existing snacks (like lowering sodium or fat) by simulating ingredient interactions, delivering healthier options without extensive trial-and-error in labs. This data-driven innovation ensures that product launches are both faster and more aligned with consumer trends, giving companies a competitive edge in crowded markets.
Scientific Discovery and Pharma R&D
In more research-intensive fields such as pharmaceuticals and materials science, generative AI is breaking new ground by designing entirely new molecular structures and compounds. A notable case is Insilico Medicine, a biotech company that used generative AI to design a novel drug molecule in record time. Insilico's AI system (dubbed GENTRL) was tasked with finding new molecules that could inhibit a protein (DDR1 kinase) implicated in fibrosis. Astonishingly, the AI generated six promising new compounds in just 21 days, a process that typically takes scientists many months. Out of these, several showed strong activity in biological assays, and one lead candidate demonstrated good effectiveness in a preclinical test in mice. This AI-designed molecule advanced to further development, illustrating how generative models can vastly expedite early-stage drug discovery.
Traditionally, drug discovery is like searching for a needle in a haystack, screening countless molecules to find a few hits. Generative AI flips this paradigm by creatively suggesting molecular structures that fit the desired criteria (shape, chemical properties, target binding) without brute-force testing of each option. Pharmaceutical giants and startups alike are now using such AI platforms to generate ideas for new drugs (for cancer, antibiotics, etc.), cutting the search time from years to days in some cases. While human chemists still must synthesize and validate the AI's suggestions, the R&D efficiency gains are game-changing.
Software and Content Development
Generative AI also boosts R&D productivity in software engineering and digital product development. AI coding assistants, the best-known being GitHub Copilot (powered by OpenAI Codex), help developers generate code snippets or even entire functions based on natural-language prompts. This has sped up programming tasks significantly. Internal studies showed that developers using Copilot completed tasks 55% faster than those coding without AI assistance. In practice, this means feature prototypes can be built in days instead of weeks. Tech companies like Netflix utilize AI not only to personalize content for users, but also to aid their software teams in rapid development and testing of new product features.
Beyond coding, generative AI can create synthetic data (for testing or training models), design user interface layouts, or even generate game assets and levels in the entertainment industry. For instance, game developers are exploring AI tools to generate virtual environments and characters, accelerating the creative process in R&D for new games. All these applications boil down to a common theme: generative AI acts as a force-multiplier for human creativity and problem-solving. It can explore a solution space at high speed, whether that space is physical designs, chemical compounds, or lines of code, and present the most viable options to human experts.
Real-world Impact
Companies adopting generative AI in R&D report tangible benefits: shorter time-to-market, improved product performance, and greater innovation output. A McKinsey analysis notes that leading firms are using AI to "size potential markets, analyze competitor moves, and estimate the value of different strategic initiatives across multiple scenarios" during product strategy and design. The R&D function, once reliant purely on human trial-and-error and experience, is becoming more data-driven and simulation-driven. That said, human expertise remains crucial, engineers and scientists guide the AI (by setting goals and validating results) and add the contextual judgment that AI lacks. When properly integrated, generative AI in R&D can significantly de-risk innovation: teams can test far more ideas virtually, catching failures early and doubling down on winners. From designing the next electric vehicle to formulating a new cosmetic, generative AI is fast becoming an indispensable tool in the innovator's toolkit, driving a new era of faster and smarter product development.
8.4 HRM: AI for Talent, Hiring, and Employee Support
Human Resource Management might seem like a domain focused on people, recruiting them, developing them, engaging them, and it is. But it's also a domain ripe for intelligent automation. Generative AI in HRM is helping organizations attract talent, streamline hiring processes, personalize training, and enhance employee self-service. The technology adds value by handling repetitive or communication-intensive tasks (like writing job descriptions or answering common employee queries) and by uncovering insights in vast HR data (like scanning resumes or crafting career development plans). For time-pressed HR teams, generative AI acts as a digital assistant that increases efficiency and allows human HR professionals to focus on strategic, interpersonal aspects of their role.
Talent Sourcing and Recruitment
Finding the right candidates is a perennial challenge. Generative AI can improve this through intelligent resume screening, automated outreach, and even drafting job postings that attract a broader talent pool. For example, RingCentral, a cloud communications company, faced slow, manual processes in sourcing specialized talent. By working with an AI talent platform (Findem), RingCentral was able to automatically comb through 1.6 trillion data points from internal and external sources to identify candidates that matched very specific criteria. The AI not only matched resumes to job requirements but also drafted personalized outreach messages. The result was a 40% increase in the candidate pipeline and a 22% improvement in candidate quality, including a 40% boost in applicants from under-represented groups.
Generative AI's ability to understand job requirements and describe them compellingly is also being leveraged by platforms like LinkedIn. In 2023, LinkedIn introduced AI-powered tools that help recruiters write better job descriptions by entering a few key details and letting GPT-3.5 generate a polished draft. This not only saves recruiters time (LinkedIn noted it "does the heavy lifting" in composing the text) but also helps ensure the language is inclusive and appealing, which can attract a wider array of candidates.
In fact, T-Mobile used an AI writing assistant (Textio) to review and enhance the wording of its job postings and recruiting emails, to mitigate unconscious bias and improve diversity in hiring. By integrating the tool into their workflow and even into their Workday applicant tracking system, T-Mobile's recruiters got real-time suggestions for more inclusive language, helping the company make faster progress on its diversity goals. These examples show AI's dual benefit in recruitment: efficiency gains (faster sourcing and communication) and higher quality outcomes (more diverse, well-matched candidates).
Streamlining Hiring Processes
Once candidates are in the pipeline, generative AI can continue to optimize the hiring funnel. Mastercard, for instance, dealt with an enormous volume of applications as the company expanded. They implemented an AI-driven talent platform (Phenom) that automates parts of the hiring journey, from scheduling interviews (using AI to match calendars) to answering candidate FAQs via chatbots. The impact was dramatic: interview scheduling was 85% faster, with 88% of interviews booked within 24 hours of the request. Moreover, by enhancing their career site with AI (including features for candidates to join talent communities and receive tailored job recommendations), Mastercard saw a 900% increase in its candidate database and ultimately added 2,000+ new hires sourced through these AI-powered channels. What would have required a much larger recruiting team (to manually chase schedules and follow up with hundreds of thousands of applicants) was accomplished with intelligent automation.
Another growing practice is using AI to conduct preliminary candidate assessments: for example, AI video interview platforms that pose questions and evaluate responses. Unilever (in Europe) famously used an AI video interview system to screen early-stage candidates, analyzing their word choices and facial expressions to identify high-potential hires, which saved recruiters countless hours. Generative AI takes this further by potentially simulating "role-play" interviews or crafting custom interview questions on the fly based on a candidate's resume. While companies must be cautious and ensure fairness (to avoid bias in AI decisions), these tools can make hiring faster, fairer, and more engaging for candidates.
Employee Self-Service and HR Support
HR departments field endless employee questions, about benefits, payroll, policies, or IT issues, which can overwhelm HR staff. Generative AI-powered HR chatbots and digital assistants can handle a large portion of these routine queries instantly and accurately. A great example comes from Manipal Hospitals in Asia (India), which deployed an HR virtual assistant named MiPAL using a generative AI platform (Leena AI). Employees, nurses, doctors, administrative staff, can ask MiPAL questions via chat or mobile app, like "How do I download my payslip?" or "How many vacation days do I have left?" The AI understands the natural language question and pulls up the relevant information or policy. By doing so, MiPAL reduced the average time to resolve employee questions from two days to 24 hours, and saved over 60,000 hours of staff time in a year. Importantly, automating the routine inquiries freed up HR team capacity to focus on more strategic initiatives (like talent development and employee engagement).
Similarly, Straits Interactive, a data governance firm in Singapore, built a generative AI assistant to help employees understand complex data privacy regulations. Their AI Data Protection Officer could interpret legal texts and answer questions in plain language, making compliance knowledge accessible without needing an expert every time. This is a form of AI-driven training and support, ensuring that employees have on-demand guidance. In large organizations, one can imagine each employee having a personal "AI HR advisor" available 24/7 for queries or even career advice (e.g., "What training courses should I take to be eligible for a promotion?"). This level of personalization at scale was never feasible before. As Unilever's HR leaders have noted, they aim to use generative AI to "increase employee engagement and retention while lowering the workload of HR staff", essentially to provide high-touch support through high-tech means.
Learning and Development
Another HR area seeing generative AI impact is employee training and development. AI can generate customized learning content, like training manuals, quiz questions, or even simulated role-play scenarios for practice. For example, a sales team could use a generative AI tool to simulate customer interactions (the AI plays the role of a difficult customer, allowing the employee to practice responses). There are already platforms where AI generates coaching tips or performance review drafts based on an employee's achievements. LinkedIn's generative AI features extend to LinkedIn Learning, where new courses on AI are being added and AI might eventually tailor learning paths for users. In performance management, managers are using AI to help draft more effective and unbiased performance evaluations by analyzing an employee's contributions and writing a first pass of feedback for the manager to refine. These uses are still emerging, but they hint at a future where AI plays a supportive role throughout the employee lifecycle, from hire to retire.
HRM Use Cases and Outcomes
Table 8.2 summarizes a few real-world generative AI applications in HR and their results:
| Company (Region) | HR Application of GenAI | Outcome/Benefit |
|---|---|---|
| RingCentral (US) | AI-driven talent sourcing & outreach | +40% candidate pipeline; +22% quality; +40% diversity in candidates. |
| Mastercard (Global) | AI automation in recruiting (scheduling, CRM) | 85% faster interview scheduling; 900% more candidate profiles in talent pool. |
| Manipal Hospitals (India) | HR chatbot for employee queries (Leena AI) | New hire attrition down 5%; query resolution time cut from 2 days to 24h; 60k+ hours saved for HR staff. |
| T-Mobile (US) | AI text assistant for inclusive job posts (Textio) | More inclusive language in all recruitment content, helping increase diversity of applicants (qualitative improvement). |
| LinkedIn (Global) | GPT-powered writing for job descriptions and profiles | Faster posting creation; job posts optimized to attract relevant talent, profiles enhanced for recruiters (productivity boost, 2x more opportunities for AI-refined profiles). |
| Straits Interactive (Singapore) | Generative AI "advisor" for data privacy (internal knowledge) | Employees get instant, layman explanations of complex policies; reduces reliance on expert HR/legal staff for routine guidance. |
These examples underline that HR is becoming more data- and AI-driven. Importantly, generative AI in HRM must be implemented with care to avoid pitfalls. Issues of fairness, transparency, and ethics are paramount: for instance, ensuring an AI model doesn't inadvertently favor or reject candidates based on biased patterns in historical data. HR leaders are mindful to keep humans "in the loop," using AI to assist rather than fully decide on hires or promotions. When done right, generative AI can make HR processes more human by freeing time for relationship-building and coaching, and by providing personalized support to each employee or candidate. As one HR executive noted, AI can handle the grunt work, allowing HR professionals to "be more strategic and enhance their impact". From global corporations to startups, HR teams across the US, Europe, and Asia are piloting these tools to compete for talent and improve the employee experience. In summary, generative AI is enabling HRM to deliver faster hiring, smarter talent management, and a better workplace experience, all while operating at a greater scale than ever before.
8.5 General Management and Strategy: Decision Support, Productivity, and Innovation
At the highest levels of management and strategy, generative AI is proving to be a transformative ally. Business leaders and strategists are leveraging AI to analyze complex data, generate insights, support decision-making, and even formulate strategy options. In day-to-day management, generative AI tools are helping draft reports, summarize market research, prepare presentations, and streamline communication. For strategic planning, AI can rapidly produce scenario analyses or comb through competitive intelligence to suggest strategic moves. The overall impact is that executives and managers can make more informed decisions faster, supported by AI-generated knowledge and recommendations.
Enhanced Decision Support and Analysis
One of the challenges in management is digesting overwhelming amounts of information, financial reports, market research, news, internal data, to make timely decisions. Generative AI (particularly large language models like GPT-4) excels at summarizing and synthesizing information. Managers can ask an AI assistant to "Summarize the key trends in our quarterly sales report" or "Give me a SWOT analysis based on these 50 pages of market research". The AI will generate a concise briefing, saving hours of reading.
For example, wealth management firm Morgan Stanley built an OpenAI-powered assistant that allows its financial advisors to query a vast library of research reports and get instant, distilled answers. Advisors can ask, say, "What's our latest outlook on European tech stocks?" and the AI will pull from internal research and generate a helpful summary or even draft an email to clients with the key points. This tool, called AI @ Morgan Stanley Assistant (with a feature named "Debrief"), automatically creates meeting summaries and follow-up notes, potentially saving thousands of hours for their 15,000 financial advisors.
The principle extends to general management: AI can act as an omnipresent analyst, crunching numbers and reading documents to answer managers' ad-hoc questions. Microsoft's Power BI, a business intelligence tool, has integrated generative AI (the new Copilot feature) that lets managers use natural language to probe data and generate visuals or insights. This means a sales manager could simply type, "Show me a chart of Q3 revenue by product line and identify the top 3 growth drivers," and the AI will produce the chart and a brief analysis, tasks that previously required a dedicated analyst. By doing in minutes what used to take days, generative AI is helping managers be more agile and data-driven.
Strategic Planning and Scenario Generation
Crafting business strategy often involves asking "what if" and considering multiple future scenarios. Traditionally, scenario planning is a time-consuming exercise done by strategy teams. Generative AI can radically speed this up by generating detailed scenario narratives and even quantitatively modeling different assumptions. According to Harvard Business Review, "GenAI can help organizations overcome inherent shortcomings in conventional processes for performing contingency scenario planning".
For instance, a strategy team can prompt an AI with something like: "Imagine three scenarios for our industry in five years: one optimistic, one moderate, one pessimistic. Describe each and the potential strategic moves we should make." The AI can produce rich narratives and even suggest strategic initiatives for each scenario. While these AI-generated scenarios are starting points (human strategists will refine and stress-test them), they significantly cut down the time needed to explore strategic options.
Consulting firms are already using such approaches with clients. Bain & Company, a leading global consultancy, formed a strategic alliance with OpenAI to embed GPT-4 into its consulting services. In one high-profile project with Coca-Cola, Bain used generative AI to help brainstorm and develop new marketing strategies and content (the Coca-Cola "Create Real Magic" campaign was an outcome of this collaboration). Beyond marketing, Bain reported that generative AI is being used to simulate market entry strategies and to generate draft strategy documents that consultants and clients can then iterate on.
Similarly, McKinsey & Company has observed that AI can "enhance every phase of strategy development, from design through execution", allowing organizations to analyze competitors, size markets, and estimate the value of strategic moves far more quickly than before. For example, if a company is considering a new product launch, AI can swiftly summarize all competitor products, patent filings, and consumer reviews in that space, giving strategists a high-level view to base their plans on. This augmentation of strategic analysis means leaders can explore more ideas with data-backed insights, ultimately making more robust decisions.
Productivity and Collaboration Tools for Management
On a day-to-day basis, generative AI is becoming like an executive assistant that never sleeps. Consider the flood of emails, memos, and documents a typical manager deals with. AI-powered tools (like Microsoft 365 Copilot and Google Workspace's Duet AI) can draft responses to emails, create first drafts of documents, and even build slide presentations from a simple outline. For instance, a manager could ask, "Draft a project update email highlighting our progress and next steps," and the AI will generate a polished email which the manager can then tweak and send. Equally, if a regional manager wants a PowerPoint on last quarter's performance, an AI can generate slides with charts and bullet points drawn from the raw data.
Global professional services firms are rapidly embracing these capabilities internally. PricewaterhouseCoopers (PwC), for example, made a $1 billion investment in AI and has become one of the largest enterprise users of ChatGPT. In 2024 PwC announced it would roll out ChatGPT Enterprise to its 75,000 U.S. and 26,000 UK employees as a productivity tool. PwC is even developing custom AI models ("private GPTs") for tasks like reviewing tax documents or generating financial reports. The goal is for consultants and auditors to complete analysis and documentation in a fraction of the time. "We are actively engaged in genAI with over 95% of UK and US consulting client accounts," PwC noted, highlighting how ubiquitous they expect AI usage to be across their business lines.
Another Big Four firm, KPMG, is integrating generative AI to assist its legal and advisory teams in drafting documents (e.g. contract analysis) and in internal knowledge management. These large-scale adoptions underscore that AI is becoming a standard part of the managerial toolkit, as common as spreadsheets or email. Managers in Asia are on the same trend; for instance, Japan's banking and telecom sectors are experimenting with bilingual AI chatbots to assist managers in summarizing English reports into Japanese and vice versa, bridging language gaps in global operations.
Corporate Strategy and Innovation
Many companies view generative AI not only as a tool for current managers but as a strategic asset for the business model itself. For example, consulting firms are productizing generative AI solutions for their clients (as seen with Bain & OpenAI, or Deloitte's AI practice building domain-specific GPT models). In the tech industry, companies like Salesforce have introduced generative AI features (Salesforce Einstein GPT) to help sales and strategy teams auto-generate insights about customer accounts and suggest next best actions. These strategic AI implementations often come from the top: executive leadership needs to champion and invest in AI capabilities across the organization.
Surveys show that as of early 2024, 72% of companies worldwide were using AI in at least one business function, up from 56% just a few years prior. Generative AI's breakout in 2023 accelerated this trend, with a majority of executives believing it will significantly impact their business in the near term. Companies are forming AI centers of excellence and training programs to raise AI fluency among managers. In Europe, for example, Siemens and Bosch have launched internal initiatives to have their managers pilot generative AI in operations and strategy, sharing best practices and success stories. The competitive advantage of using AI at the management level can be substantial: decisions get made faster and with more evidence; strategies are tested virtually before committing real resources; and the organization becomes more adaptive through continuous learning from AI-generated feedback.
In embracing generative AI for management and strategy, companies should also develop proper governance. AI-generated content can sometimes be inaccurate or might reflect biases in its training data. Therefore, leading organizations pair AI outputs with human review, a manager might use the AI's analysis but will cross-verify key facts, or use an AI's suggested strategy as one input among others (including human intuition and stakeholder consultation). When used wisely, generative AI can augment managerial judgment, not replace it. It serves as a kind of "co-pilot" for executives: crunching data, offering second opinions, proposing creative solutions, and taking over routine chores. This frees leaders to do what they do best, provide vision, empathize with employees and customers, and make the tough calls that machines alone cannot.
8.6 Conclusion: From Hype to Real Value Across the Business
As we have explored in this chapter, generative AI is already delivering real-world value across key business functions. In Marketing, it drives personalized campaigns and prolific content creation, enabling brands to engage customers in innovative ways while saving time and cost. In R&D, it accelerates product innovation cycles and solves complex design problems, whether designing a lighter airplane part or suggesting a new drug candidate. In HRM, it streamlines hiring and nurtures employees by automating repetitive tasks and providing intelligent support, making HR processes more efficient and inclusive. In General Management and Strategy, it amplifies decision-making and strategic thinking, helping leaders analyze information and formulate plans with greater speed and insight. These advancements are not just theoretical, they are backed by numerous case studies from the U.S., Europe, and Asia, as we have cited, and powered by an ever-growing ecosystem of AI tools and platforms.
Business professionals should note that while generative AI offers significant rewards, its implementation should be accompanied by thoughtful change management. Companies that have succeeded (like those mentioned, from PepsiCo to PwC) typically started with pilot projects, ensured data security and ethical use, and trained their teams to work alongside AI. The tone of this chapter has been deliberately practical and non-technical: the aim is for managers in any function to grasp how generative AI can help them and what others have achieved with it. The takeaway is that generative AI is not just a buzzword but a versatile business instrument – one that can write a marketing tagline one minute, and help draft a strategic plan the next.
In conclusion, generative AI is becoming deeply embedded in how companies operate and compete. Those in marketing find it a creative partner; those in R&D see it as an innovation catalyst; HR leaders view it as a co-worker handling routine queries; and executives treat it as an ever-ready advisor. The technology is still evolving, and undoubtedly, new applications will emerge beyond the functions covered here (imagine AI in finance for fraud detection or in supply chain for dynamic route optimization, which other chapters touch upon). But as of Chapter 8, we stand at a point where generative AI has moved from concept to pilot to broad adoption in many enterprises. It is reshaping job roles and required skills – emphasizing that while AI can generate content or ideas, human judgment, creativity, and empathy remain irreplaceable. The organizations that blend the two effectively are already reaping benefits: higher efficiency, enhanced creativity, better decisions – and ultimately, greater business value in the real world.
As you consider your own business or functional area, the question is no longer "Should we use generative AI?" but rather "How can we best use generative AI to augment our capabilities and achieve our objectives?" The case studies and examples in this chapter serve as inspiration and guidance for that journey into the new era of AI-powered business.
Chapter 9: The EDGE Framework for GenAI Value Creation
For business leaders, the flood of Generative AI hype is overwhelming. The conversation is often lost in technical jargon rather than focused on the single most important question: How does this technology create tangible value for my business?
While the "Five A's" (Access, Assistants, Application, Automation, and Agents) discussed in the previous chapter provide a map of what the tools are, we now need a framework for why we deploy them. We must move from a features-first to a value-first mindset.
This chapter introduces the EDGE Framework, a simple yet powerful model for managers to identify, prioritize, and execute on the four primary sources of Generative AI value. This framework helps you cut through the noise and build a practical business case for AI adoption, linking every initiative to a core strategic driver.
The four pillars of the framework are:
- Efficiency
- Decisions
- Growth
- Empowerment
We will explore each pillar not as a simple checklist, but as a strategic path, moving from immediate operational gains to long-term market transformation.
9.1 E = Efficiency (Securing the Foundation)
The most immediate and measurable value of Generative AI lies in optimizing your current operations. This is the "low-hanging fruit" and the foundation upon which all other AI ambitions are built.
Definition: Efficiency gains come from the automation and standardization of repetitive, high-volume tasks. This is about doing what you already do, but faster, cheaper, and at a greater scale.
Example in Action: A financial services firm uses Generative AI to automatically summarize earnings call transcripts, generate first drafts of quarterly compliance reports, and create routine client communications. A process that previously consumed 200 person-hours monthly now only requires 20 hours of high-level human review and refinement.
Why This Matters for Managers: This is your "quick win." For leaders, this pillar is the most direct path to a measurable ROI. It directly impacts your bottom line and resource allocation by reducing costs and accelerating turnaround times. By freeing your team from low-value, repetitive work, you liberate their time and cognitive energy to focus on the strategic priorities that truly matter. This is often the easiest business case to build and the best way to secure organizational buy-in and funding for broader AI initiatives.
9.2 D = Decisions (Gaining a Strategic Advantage)
Once you have freed up resources through Efficiency, the next level of value creation is not just to do things faster, but to think better. This pillar focuses on using AI to enhance the quality and speed of managerial and strategic decision-making.
Definition: This is about making better, faster choices by using AI to synthesize context-rich insights from massive, complex, and often unstructured data sets.
Example in Action: A retail executive uses an AI platform to analyze millions of customer reviews, social media comments, competitor pricing data, and supply chain signals simultaneously. The system identifies an emerging trend showing customers are willing to pay a premium for sustainable packaging. This was a weak signal, buried across fragmented data sources that no single analyst or team would have connected, but it provides a clear path for a new product and pricing strategy.
Why This Matters for Managers: This pillar is your defense against uncertainty. It reduces decision-making risk in volatile environments and provides competitive intelligence at a speed and scale impossible for human analysts alone. This allows you to spot opportunities and threats earlier than your rivals. It is particularly valuable when you face complex choices with incomplete information, which describes most high-stakes strategic decisions.
9.3 G = Growth (Defining the Future Market)
With efficient operations and smarter decisions, you can move from a defensive to an offensive strategy. This pillar is the most transformative. It is not about optimizing your current business model; it is about creating entirely new ones.
Definition: Growth is achieved by creating AI-native products, services, and operating models that unlock new revenue streams and fundamentally reshape your competitive advantage.
Example in Action: A traditional legal software company launches an AI-powered research assistant. This tool doesn't just search documents; it generates custom legal memos, predicts case outcomes based on precedent, and drafts initial briefs. This isn't an "add-on" feature—it's a fundamentally new product category that could not exist without Generative AI, opening an entirely new market segment and rendering older search-based tools obsolete.
Why This Matters for Managers: This defines your future revenue and market position. While competitors are focused on Efficiency, this pillar is about creating offerings that can make current solutions obsolete, including potentially your own. This is critical for long-term survival and leadership as AI reshapes industry boundaries. It helps you move from a defensive posture ("How do we protect our current business?") to an offensive one ("How do we lead the next wave?").
9.4 E = Empowerment (The Human Accelerator)
The first three pillars (Efficiency, Decisions, Growth) are the outcomes. The final pillar, Empowerment, is the enabler. It is the human-centric engine that powers all the others. You cannot achieve efficiency, make better decisions, or create new growth without elevating your workforce.
Definition: Empowerment is the augmentation of human capability and creativity. It elevates your workforce to operate at higher levels of expertise and output by equipping them with AI tools that act as co-pilots, mentors, and creative partners.
Example in Action: A consulting firm equips every junior analyst with an AI assistant trained on the firm's proprietary frameworks and past projects. These analysts can now draft initial strategy frameworks, generate complex data visualizations, and research industry precedents in minutes, not days. As a result, junior analysts produce work quality that previously required 5+ years of experience. This allows senior consultants to focus exclusively on high-value client relationship building and strategic problem-solving.
Why This Matters for Managers: This is the solution to your talent challenges, including skills gaps, hiring difficulties, and employee retention. It dramatically accelerates employee development and flattens the expertise curve, allowing smaller, leaner teams to compete with larger organizations. Critically, it improves employee satisfaction and engagement by removing tedious, "busy work" and allowing them to focus on more meaningful contributions. This is about making your people better, not replacing them.
9.5 From Framework to Action: Implementing the EDGE Strategy
The EDGE Framework identifies where to find value. The next step is how to capture it. A successful GenAI strategy does not happen overnight; it follows a clear, phased transformation roadmap.
Phase 1: Exploration & Awareness
This is where you educate your leadership and teams. You use the EDGE framework to identify initial, high-value use cases (often starting with "E" for Efficiency). You also assess your current tech landscape and skill gaps.
Phase 2: Pilot & Experimentation
Here, you launch small-scale, cross-functional projects to test your hypotheses from Phase 1. You implement and test solutions, measure KPIs (tracking efficiency, decision quality, etc.), and gather user feedback. This is where you prove the ROI in a controlled environment.
Phase 3: Integration & Scaling
Once a pilot is successful, you move to full-scale implementation. This requires developing a robust infrastructure (cloud platforms, data pipelines) and, most importantly, establishing governance.
As you scale, a formal GenAI Governance Framework becomes non-negotiable. This must include:
- Data Governance: Clear policies for data quality, privacy, and ethical use.
- Security: Protocols to protect your intellectual property (IP) and defend against malicious AI use.
- Legal & Compliance: Guidelines for copyright, IP, and evolving regulations.
- Ethics: A company-wide responsible AI policy that ensures transparency and accountability in every application.
9.6 Conclusion: Using EDGE as a Strategic Compass
The EDGE Framework provides a clear-thinking manager's guide to Generative AI. It moves beyond the hype and provides four distinct, actionable pillars of value creation.
Start with Efficiency to secure your foundation and fund your journey.
Use those gains to improve your Decisions and build a strategic advantage.
Leverage your new capabilities to pursue transformative Growth.
And underpin every step with Empowerment to accelerate and elevate your entire workforce.
As a leader, your role is to use this framework as a strategic compass. You can now look at any proposed AI project and ask: "Which part of the EDGE is this serving? Is it an 'E', a 'D', a 'G', or an 'E'?" This simple question will ensure that every dollar you invest in AI is driving real, measurable, and strategic business value.
Chapter 10: The Strategic Roadmap for GenAI Implementation
Understanding what Generative AI is (The Five A's) and why it creates value (The EDGE Framework) is the necessary foundation for any leader. The final, and most critical, question is how to implement it. Moving from isolated experiments to an enterprise-wide capability is a complex journey that requires a clear plan.
A successful Generative AI strategy is not a single project; it is a phased transformation. This chapter outlines a practical, three-phase roadmap designed to move your organization from initial curiosity to full-scale implementation, ensuring that you build momentum, manage risks, and deliver tangible value at every step.
The Three-Phase Transformation Roadmap: This roadmap is a structured approach to build your organization's "AI muscle." It begins with foundational learning, moves to real-world testing, and culminates in scaling the solutions that deliver proven value.
10.1 Phase 1: Exploration & Awareness (Foundation Building)
The goal of this first phase is to create a common language, get leadership buy-in, and map your technological and human landscape. This is where you set the foundation for everything that follows.
1.A Educate Leadership & Teams: You cannot lead a transformation you do not understand. The first step is to demystify Generative AI for everyone from the C-suite to frontline managers. This is achieved through structured education:
- Workshops & Seminars: Interactive sessions focused on the "why" (the EDGE framework) and the "what" (the Five A's), tailored to specific business units.
- Online Courses: Providing self-paced learning resources for teams to build baseline knowledge.
1.B Identify Initial Use Cases: With a shared understanding, you can begin brainstorming. The goal is not to find every possible use case, but to identify the first valuable ones.
- Start with "E" (Efficiency): Use the EDGE framework as your guide. The easiest and fastest wins are almost always in Efficiency (e.g., content creation, data analysis, process automation).
- Prioritize: Map these use cases on a simple matrix of "Value vs. Feasibility" to find the high-value, low-complexity projects to tackle first.
1.C Assess Current Tech Landscape: You cannot build a high-tech solution on a low-tech foundation. This step is a realistic audit of your current capabilities.
- Existing Data Infrastructure: Is your data accessible, clean, and secure? AI is powered by data; this is non-negotiable.
- Software Compatibility: Do your current systems have the APIs needed to connect to AI tools?
- Skill Gaps: Do you have people who understand data science, cloud platforms, and AI? Be honest about what you have versus what you will need to hire or train.
10.2 Phase 2: Pilot & Experimentation (Real-World Application & Learning)
The goal of this phase is to move from theory to practice. You will test your hypotheses from Phase 1 in a controlled, low-risk environment to prove what works.
2.A Initiate Small-Scale Projects: Do not try to "boil the ocean." Select 1-3 of the high-priority use cases you identified and launch small, focused pilot programs.
- Targeted Departments: Choose a specific team that is eager to experiment.
- Specific Use Cases: Be precise (e.g., "Use AI to draft first-round marketing copy for A/B testing," not "Fix marketing").
- Cross-functional Teams: Build a "tiger team" with members from IT, the business unit, and legal/compliance to ensure all angles are covered.
2.B Implement & Test Solutions: This is the "lab" phase. Your team will build, deploy, and iteratively test the AI solution.
- Model Deployment & Data Integration: This involves connecting the AI model (an "Access" model) to your data and workflows (an "Automation" or "Application").
- Iterative Prototyping: The first version will not be perfect. The goal is to get a functional prototype into users' hands quickly, gather feedback, and refine it.
2.C Measure & Gather Feedback: A pilot is useless without clear metrics. You must define success and measure it.
- KPI Tracking: Refer back to your EDGE framework. If you targeted Efficiency, measure the reduction in person-hours. If you targeted Decisions, measure the speed or quality of the insight.
- User Acceptance Testing: Do the actual users find the tool helpful? Does it integrate into their workflow, or does it add friction?
- Post-Pilot Analysis: At the end of the pilot, you must have a clear "Go/No-Go" decision, backed by data, on whether to scale the solution.
10.3 Phase 3: Integration & Scaling (Full-Scale Implementation)
Once a pilot has proven its value, you enter the final phase: scaling the solution to the entire enterprise. This is where you move from a "project" to a "platform."
3.A Develop Robust Infrastructure: What works for a 10-person pilot will break for a 10,000-person enterprise. This step is about building the industrial-grade infrastructure.
- Cloud-Based Platforms: Securing the necessary cloud computing resources.
- Data Pipelines & APIs: Building the "plumbing" to move data securely and reliably across the organization.
- Security Protocols: Hardening your systems to protect your intellectual property and customer data.
3.B Establish Governance & Ethics: This is the single most important step for scaling. You cannot give powerful tools to your entire workforce without clear rules of the road. This is so critical that we will detail it in its own section below.
3.C Scale Successful Use Cases: With the infrastructure and governance in place, you can now "turn on" the AI for everyone.
- Enterprise-Wide Deployment: Rolling out the proven solution to all relevant departments.
- New Departmental Applications: Taking the lessons learned from the first pilot and quickly applying them to new use cases.
- Training & Support: You must have a plan to train thousands of employees and a support system (like a help desk or "AI Champions") to manage the change.
10.4 Key Pillars for Scaling: Governance and Operating Model
The leap from Phase 2 to Phase 3 often fails, not because of technology, but because of a lack of governance and a clear operating model.
10.4.1 The GenAI Governance Framework
As you scale, you must have a formal governance framework that includes:
- Data Governance: Clear policies for data quality, privacy, and ensuring ethical use of customer and company data.
- Security: Protocols to protect your firm's intellectual property (IP) from being leaked into public models and to defend against new AI-driven security threats.
- Legal & Compliance: Clear guidelines for copyright, IP ownership of AI-generated content, and how to navigate the rapidly evolving regulatory landscape.
- Ethics & Responsible AI: A company-wide policy that ensures transparency (when is an employee/customer interacting with an AI?) and accountability (who is responsible when an AI makes a mistake?).
10.4.2 Building the GenAI Operating Model
Technology and governance provide the "what." The operating model defines the "who" and "how." You must decide how AI capabilities will be structured, staffed, and socialized within your organization. This model is built on three pillars: Operating Structure, Talent Strategy, and Change Management.
1. Operating Structure: Centralized, Decentralized, or Hybrid?
This is the foundational choice of how to organize your AI talent and resources.
Centralized (Center of Excellence - CoE):
- What it is: A single, central team of AI experts (data scientists, ML engineers, ethicists) that serves the entire organization. All AI projects are routed through this group.
- Pros: Enforces strong governance and standards. Prevents duplication of effort. Consolidates deep expertise. Highly efficient for building large, complex, foundational models.
- Cons: Can quickly become a bottleneck, slowing down innovation. The CoE can become detached from the specific needs of individual business units, leading to solutions that are technically sound but practically useless.
- Best for: Highly regulated industries (finance, healthcare) or organizations just beginning their AI journey that need to maintain tight control.
Decentralized (Embedded Model):
- What it is: AI talent is hired directly into and managed by individual business units (e.g., Marketing has its own AI squad, Finance has its own).
- Pros: Extremely fast and agile. Deeply aligned with business unit goals, resulting in highly relevant solutions. Fosters a culture of rapid prototyping and innovation.
- Cons: Can lead to "shadow AI," with redundant tools and wasted resources. Creates massive inconsistencies in governance, security, and quality. Expertise remains siloed, preventing cross-functional learning.
- Best for: Highly dynamic, tech-forward companies with a strong existing engineering culture where speed-to-market is the primary driver.
Hybrid (Federated Model):
- What it is: The most common and effective model. It combines the best of both worlds.
- How it works: A central CoE sets the "guardrails": governance, security policies, ethical guidelines, preferred vendors, and the core technology platform. Then, "AI Champions" or small, embedded squads within business units are empowered to build their own solutions within those guardrails.
- Best for: Most mature organizations. This model balances centralized control (for safety and efficiency) with decentralized execution (for speed and relevance). It provides "freedom within a framework."
2. Talent Strategy: Build, Buy, or Borrow?
Your operating structure is useless without the right people. Your talent strategy must be a two-pronged approach.
Reskilling & Upskilling (The "Build" Strategy): This is your internal game, focused on creating broad AI literacy.
- AI Literacy for All: Every employee must understand the basics of what GenAI is, how to use it safely (e.g., data privacy, "hallucinations"), and the new governance policies.
- "AI Champions" Program: Identify and train power users within each business unit. These champions become the local go-to experts, reducing the burden on IT and evangelizing AI use.
- Technical Upskilling: Create clear learning paths for your existing IT, data, and analytics staff to become proficient in AI/ML operations and data engineering.
Acquisition (The "Buy" Strategy): This is your external game, focused on hiring for highly specialized, deep expertise that you cannot build internally.
- "AI Ethicist" / "AI Governance Specialist": Roles that are no longer "nice to have" but critical. They help navigate the legal, ethical, and compliance risks of scaling AI.
- "AI/ML Ops Engineer": A specialized engineering role focused on the unique challenges of deploying, monitoring, and managing AI models in production.
- "AI Product Manager": A crucial bridging role. This person understands both the technical capabilities of AI and the strategic needs of the business, ensuring you build solutions that create real value.
3. Change Management: The Human-Side of Transformation
This is the most important and most frequently failed pillar. A brilliant AI strategy will be defeated by a fearful or resistant culture.
- Address the Fear Head-On: Do not ignore the "job replacement" anxiety. Acknowledge it publicly and reframe the narrative from Replacement to Empowerment. Use the EDGE framework: AI is here to remove tedious work (Efficiency) and elevate your skills to be more strategic (Empowerment).
- Communicate the "WIIFM": Clearly answer "What's In It For Me?" for every employee. Use concrete results from your Phase 2 pilots. (e.g., "The finance pilot automated 20 hours of manual report-pulling per week, freeing the team to focus on strategic analysis.").
- Executive Sponsorship is Non-Negotiable: The CEO and other leaders must visibly and vocally champion the AI transformation. If AI is seen as "an IT project," it will fail. It must be communicated as a core business strategy, and leaders must be seen using the tools themselves.
- Create Clear Communication Channels: Establish a single source of truth (an intranet portal, a regular newsletter) for AI updates, success stories, policy changes, and training opportunities. This prevents misinformation and builds momentum.
10.5 Conclusion: A Continuous Journey
This three-phase roadmap provides a clear path from idea to impact. It is not a one-time checklist but a continuous cycle. As you scale successful projects, you will identify new use cases, which will require new pilots and further scaling.
By following a structured roadmap, you move Generative AI from a source of hype and anxiety to a predictable, manageable, and powerful engine for value creation, ultimately transforming your organization one phase at a time.
Chapter 11: Navigating the Ethical Landscape
11.1 Introduction
Generative Artificial Intelligence (GenAI) is rapidly reshaping the business world, demonstrating transformative potential across diverse functions such as marketing, software development, customer operations, and R&D. This technology promises to unlock trillions of dollars in value, potentially adding $2.6 trillion to $4.4 trillion annually across various use cases. However, this wave of innovation brings with it a complex web of ethical, societal, regulatory, and legal challenges that businesses must navigate with foresight and responsibility.
While the opportunities are immense, organizational preparedness lags significantly. A striking report revealed that only one in ten organizations has adequately prepared for forthcoming GenAI regulations, and an alarming 95% lack a comprehensive governance framework for GenAI. This gap underscores the critical need for businesses to proactively address the multifaceted risks associated with GenAI adoption.
This chapter aims to provide a comprehensive guide through this intricate landscape. We will work on the core ethical considerations inherent in GenAI, explore its profound impact on the workforce and society, analyze the burgeoning global regulatory frameworks, and scrutinize the legal implications and compliance requirements for businesses. The core objective is to equip business leaders, professionals, and policymakers with the nuanced understanding necessary to make informed decisions, foster responsible GenAI adoption, and harness its power for sustainable and equitable growth.
Chapter Focus:
- The dual nature of GenAI: a catalyst for innovation versus a source of significant risk.
- The urgent imperative for establishing robust ethical principles and governance structures within organizations.
- A structured exploration of ethical dilemmas, societal transformations, regulatory requirements, and legal liabilities pertinent to GenAI in business.
11.2 Ethical Considerations of Generative AI
The development and deployment of Generative AI in business contexts raise a host of ethical dilemmas that demand careful consideration. These concerns span from biases embedded in algorithms to the environmental cost of training large models. Addressing these issues proactively is paramount for building trust and ensuring responsible innovation.
9.2.1 Bias and Fairness
A primary ethical concern with GenAI is the potential for bias embedded within its training data to be perpetuated and even amplified in its outputs. If the data used to train AI models reflects historical or societal biases, the AI system can produce outcomes that are discriminatory. This is particularly problematic in sensitive applications such as recruitment, loan approvals, and customer profiling. For instance, one case highlighted the real-world impact of algorithmic bias where AI-powered recruiting software automatically rejected older applicants. Such biases can lead to unfair treatment, reduced opportunities for certain demographic groups, and the reinforcement of systemic inequalities. The challenge lies not only in identifying these biases, often deeply woven into vast datasets, but also in mitigating them effectively to achieve true fairness across diverse populations. Compounding this issue, a recent report indicates that only one in twenty organizations (5%) has a reliable system to measure bias and privacy risk in Large Language Models (LLMs), underscoring a significant gap in current practices.
9.2.2 Accountability and Transparency (Explainability/Interpretability)
Many advanced GenAI models, particularly deep learning systems, operate as "black boxes," making it difficult to understand the precise reasoning behind their outputs or decisions. This lack of transparency poses significant challenges for accountability. If a GenAI system causes harm, makes a critical error, or generates problematic content, determining responsibility becomes complex. The "Lack of explainability and interpretability" has been highlighted as a major concern. The development of Explainable AI (XAI) techniques is crucial for building trust with users, enabling effective auditing, debugging systems, and establishing clear lines of accountability for AI-generated actions and content. Without explainability, it is challenging to identify whether a flawed output is due to biased data, faulty model architecture, or other unforeseen factors.
9.2.3 Data Privacy and Security
GenAI models are trained on vast quantities of data, which can often include personal, sensitive, or confidential information. The collection, storage, and processing of this data present substantial privacy risks. Organizational concerns are high, with one report finding that 76% of organizations are concerned about data privacy and 75% about security with GenAI. There's a risk of unauthorized use of personal data in training sets, data breaches exposing sensitive information, and even the potential for GenAI systems to inadvertently reveal private information through their outputs. For example, AI trained on personal medical histories could generate synthetic profiles closely resembling real patients, leading to privacy concerns and potential Health Insurance Portability and Accountability Act (HIPAA) violations. Ensuring compliance with data protection regulations like GDPR and CCPA, effectively anonymizing training data, and securely handling user inputs are critical challenges for businesses deploying GenAI.
9.2.4 Misinformation and Disinformation (Harmful Content & "Hallucinations")
GenAI systems can create highly realistic but false or misleading content, including text, images, audio, and video ("deepfakes"). They are also prone to "hallucinations," where the AI confidently presents fabricated information as fact. For example, some chatbots have been known to fabricate citations to non-existent sources, and one chatbot falsely accused an NBA star of vandalism. The potential for widespread dissemination of such AI-generated misinformation poses serious threats to brand integrity, public trust, and societal stability. The "Distribution of harmful content" is identified as a primary ethical risk. Businesses have an ethical responsibility to implement safeguards against the creation and spread of harmful content when deploying GenAI, particularly in content generation and customer-facing applications. Detecting and combating AI-driven misinformation remains a significant technical and ethical challenge.
9.2.5 Intellectual Property and Copyright
The use of copyrighted materials to train GenAI models without explicit permission raises significant ethical and legal questions. If models are trained on text, images, code, or music scraped from the internet, they may inadvertently learn and reproduce protected works. This has led to numerous lawsuits from creators and rights holders. Simultaneously, the copyright status of works generated by AI is a contentious issue. Current legal frameworks generally require human authorship for copyright protection, leading to debates about whether and how AI-generated content can be owned or protected. Ensuring training content is licensed is emphasized as important, and the complexities around IP rights for both training inputs and AI-generated outputs are widely discussed. Navigating the tension between fostering innovation with GenAI and respecting the rights of creators requires new ethical frameworks and potentially, evolving legal interpretations or licensing models.
9.2.6 Environmental Impact
Training large-scale GenAI models, especially foundation models, is computationally intensive and consumes significant amounts of energy. This has led to concerns about the carbon footprint associated with GenAI development and deployment. "Carbon footprint" is listed as one of the biggest concerns in GenAI ethics. The ethical challenge lies in balancing the pursuit of technological advancement and the potential benefits of GenAI against its environmental cost. This calls for research into more energy-efficient algorithms, hardware, and responsible deployment strategies that consider sustainability.
9.2.7 Other Considerations
Beyond the above, several other ethical considerations warrant attention:
- Shaping Public Opinion and Amplifying Voices: AI algorithms can influence the information individuals see, potentially shaping public opinion and disproportionately amplifying certain viewpoints while marginalizing others.
- Sensitive Information Disclosure: There's a risk that GenAI systems, if not properly secured or if user inputs are mishandled, could lead to the inadvertent disclosure of sensitive personal or corporate information.
- Data Provenance: Understanding the origin and lineage of data used to train GenAI models is crucial for assessing its reliability, potential biases, and compliance with legal and ethical standards. Lack of clarity in data provenance can obscure accountability.
11.3 Impact on Workforce and Society
Generative AI is poised to induce substantial transformations in the labor market and broader societal structures. Its capabilities extend beyond automating routine tasks to influencing cognitive work, creative processes, and the very fabric of our information ecosystem. Understanding these multifaceted impacts is crucial for navigating the transition responsibly.
9.3.1 Impact on the Workforce
Job Displacement and Creation
A significant concern surrounding GenAI is its potential for job displacement. It has been estimated that "half of today's work activities could be automated between 2030 and 2060," accelerating the pace of workforce transformation. This automation is not limited to manual or routine tasks; GenAI can impact roles requiring cognitive skills, creativity, and complex problem-solving—jobs previously considered "safe" from automation. Polls indicate that most Americans believe GenAI will have a major, mainly negative, impact on jobs. However, alongside displacement, GenAI is also expected to create new roles, such as AI trainers, prompt engineers, AI ethicists, and specialists in AI governance and maintenance. The critical challenge lies in managing this transition, which will necessitate significant investment in reskilling and upskilling initiatives to equip the workforce for the jobs of the future.
Productivity and Skill Augmentation
GenAI also offers substantial opportunities to augment human capabilities and enhance labor productivity. It has been suggested that GenAI could enable labor productivity growth of 0.1 to 0.6 percent annually through 2040. One survey found that 72% of respondents believe generative AI could play an important role in increasing workplace productivity. It can assist with tasks like business writing, programming, complex data analysis, and customer support, allowing workers to focus on higher-value activities. This shift will likely increase demand for workers with strong technical skills, creativity, critical thinking, and emotional intelligence, abilities that complement GenAI tools rather than compete directly with them.
Worker Morale and Job Security
The prospect of AI-driven automation and workforce restructuring can understandably lead to concerns about job security and impact worker morale. The same survey that highlighted productivity benefits also found that 47% of participants expect decreased job security due to GenAI. Organizations adopting GenAI must prioritize transparent communication, involve employees in the transition process, and invest in change management strategies to mitigate anxiety and foster a positive outlook towards technological adoption.
9.3.2 Broader Societal Impact
Economic Inequality
There is a significant risk that the economic benefits of GenAI could be unevenly distributed, potentially exacerbating existing socioeconomic inequalities. One study suggests that generative AI has the potential to both exacerbate and ameliorate existing socioeconomic inequalities. If access to GenAI tools, the skills to use them effectively, and the new jobs created are concentrated among certain groups or regions, disparities in income and opportunity could widen. Proactive policy interventions and inclusive deployment strategies are necessary to promote shared prosperity and ensure that the benefits of GenAI are broadly accessible.
Information Ecosystem (Misinformation & Trust)
The capacity of GenAI to create convincing false narratives, deepfakes, and "hallucinated" facts poses a profound threat to the integrity of the information ecosystem. One article also notes that manipulated political images already constitute a substantial portion of visual misinformation on social media. This can erode public trust in digital content, complicate democratic processes, and make it increasingly difficult for citizens to distinguish fact from fiction. Addressing this requires a multi-pronged approach involving technological solutions for detection, enhanced media literacy education, and regulatory frameworks for content authenticity.
Creative Industries and Intellectual Property
GenAI presents unique challenges for creative industries. Artists, writers, musicians, and other creative professionals face concerns that their original works might be used to train AI models without consent or compensation, or that AI-generated content could devalue human creativity. It's reported that artists argue these platforms employ their unique styles to train AI, enabling users to generate works that may lack sufficient transformation from their existing protected creations. This challenges existing definitions of intellectual property and the economic models that support creative professions, sparking an ongoing debate about the value and rights associated with human versus AI-generated creative outputs.
Ethical Governance and Societal Preparedness
The rapid advancement of GenAI has, in many cases, outpaced societal and organizational preparedness to manage its implications. Data highlights significant underlying issues with data management that can impede GenAI success: 92% of surveyed participants indicated that unstructured data issues impacted their GenAI initiatives, with 30% describing this impact as "large" or "significant." Furthermore, 68% of respondents said that more than half of their files had at least one issue, and for 42%, over 70% of their files had an issue that could hinder GenAI success. Common data issues include duplicate files (66%), out-of-date information (53%), and conflicting versions (47%). This lack of foundational data hygiene, coupled with the previously mentioned low preparedness for regulations and lack of governance frameworks, points to a critical need for proactive societal dialogue, robust governance development at organizational and national levels, and investment in data infrastructure to responsibly integrate GenAI.
11.4 Global Regulatory Landscape
As Generative AI technologies become more pervasive, governments and regulatory bodies worldwide are grappling with how to foster innovation while mitigating potential risks. The regulatory landscape is dynamic and varied, reflecting different legal traditions, societal values, and economic priorities. Understanding these key international approaches is crucial for businesses operating globally.
9.4.1 European Union: The AI Act
Core Overview: The European Union has pioneered a comprehensive, risk-based legal framework with its AI Act, aiming to establish a global standard for AI regulation. The Act seeks to ensure that AI systems placed on the EU market and used within the Union are safe, transparent, traceable, non-discriminatory, and under human oversight.
Key Provisions for Businesses:
- Risk-Based Categorization: AI systems are classified into four main risk categories:
- Unacceptable Risk: Systems deemed a clear threat to the safety, livelihoods, and rights of people are banned. Examples include social scoring by public authorities, real-time remote biometric identification in publicly accessible spaces for law enforcement (with narrow exceptions), and AI that manipulates human behavior to circumvent users' free will.
- High-Risk: Systems that can adversely affect safety or fundamental rights. These are subject to stringent obligations. Examples include AI in critical infrastructure (e.g., transport), medical devices, recruitment and worker management, educational and vocational training (e.g., exam scoring), access to essential private and public services (e.g., credit scoring, except for fraud detection), and certain law enforcement, migration, and justice administration applications.
- Limited Risk: Systems like chatbots or deepfakes are subject to transparency obligations. Users must be informed that they are interacting with an AI system or that content is AI-generated.
- Minimal or No Risk: AI systems such as AI-enabled video games or spam filters face no additional specific legal obligations under the Act, though voluntary codes of conduct are encouraged.
- Requirements for High-Risk Systems: Providers of high-risk AI systems must implement robust risk management systems, ensure high-quality data governance (training, validation, and testing data), maintain extensive technical documentation, enable record-keeping (logging), ensure transparency and provide clear information to users, facilitate human oversight, and design for appropriate levels of accuracy, robustness, and cybersecurity.
- Rules for General-Purpose AI (GPAI) / Foundation Models: Specific obligations apply to GPAI models. All GPAI model providers must draw up technical documentation, comply with EU copyright law (including providing detailed summaries of copyrighted data used for training), and disseminate information to downstream providers. GPAI models presenting "systemic risks" (based on computational power used for training, or other criteria) face additional obligations, including model evaluation, systemic risk assessment and mitigation, and ensuring an adequate level of cybersecurity.
Business Implications: The EU AI Act imposes significant compliance burdens, particularly for companies developing or deploying high-risk AI systems or systemic GPAI models. Businesses will need to conduct thorough risk assessments, invest in robust governance (a critical area given that 95% of organizations currently lack a comprehensive governance framework for GenAI), ensure data quality, and prepare for potential market access restrictions if their systems are non-compliant. The Act will have extraterritorial reach, affecting businesses outside the EU if their AI systems are used within the EU market.
9.4.2 China: Regulations on Generative AI
Core Overview: China has adopted an agile and iterative regulatory approach to GenAI, characterized by government-led initiatives aiming to balance rapid technological development with state control, national security, and alignment with socialist core values. The "Interim Measures for the Management of Generative AI Services," effective August 2023, are a cornerstone, with further draft regulations continuing to evolve. China's ambition is to become a global AI leader by 2030.
Key Provisions for Businesses:
- Service Provider Obligations: Providers of GenAI services to the public in China must conduct security assessments and file algorithms with relevant authorities. They are responsible for content moderation to ensure outputs align with societal ethics and national policies, and must protect user data and respect user rights.
- Labelling Requirements: There is a mandate to clearly label AI-generated content as such (e.g., "Generated by AI") to ensure transparency for users.
- Training Data Requirements: Regulations emphasize the legality of data sources, respect for intellectual property rights, data quality and accuracy, and the prevention of discrimination in data used for training models.
- Ethical Review: Entities engaged in R&D and applications of AI systems with public opinion attributes or social mobilization capabilities are subject to ethical review obligations.
Business Implications: Businesses operating in or offering GenAI services to China must navigate complex content restrictions, ensure stringent data protection practices compliant with laws like the Personal Information Protection Law (PIPL), and be prepared for rigorous government oversight. The regulatory landscape is evolving rapidly, requiring continuous monitoring and adaptation.
9.4.3 Japan: METI Guidelines and Emerging Legislation
Core Overview: Japan has traditionally favored a "soft law" approach, promoting a human-centric vision for AI that balances innovation with safety and security. The Ministry of Economy, Trade and Industry (METI) and the Ministry of Internal Affairs and Communications (MIC) released the "AI Guidelines for Business Ver1.0" in April 2024 (with Ver1.1 Appendix released later), which are non-binding but influential. There is, however, a discernible shift towards more binding legislation, exemplified by the draft "Basic Law for the Promotion of Responsible AI".
Key Principles (from AI Guidelines for Business): The guidelines define roles and desirable voluntary actions for different entities:
- For AI Developers: Assess the potential societal impact of their AI in advance, ensure safety in development, and take measures to prevent bias in training data.
- For AI Providers: Provide clear usage instructions, information about AI capabilities, limitations, and risks to users.
- For AI Business Users: Comply with provider guidelines, use AI systems appropriately with consideration for safety, prevent inappropriate input of personal information and privacy violations, and provide feedback on incidents or issues.
The guidelines emphasize multi-stakeholder cooperation and voluntary initiatives.
Potential Future Legislation (AI Act draft): The draft Basic Law for Responsible AI is expected to introduce provisions for "frontier AI models" (high-performance, general-purpose models), potentially involving government reporting, audits, and corrective measures if risks are identified.
Business Implications: Companies in Japan should focus on responsible AI development and deployment, clearly understanding their roles and responsibilities as developers, providers, or users. Proactive risk management and adherence to the METI guidelines are advisable, even if non-binding, as they lay the groundwork for potential future mandatory regulations. Addressing data management is crucial, given that 85% of organizations manage over 1 million documents and files, and common data issues like duplicate files (affecting 66%) can hinder GenAI performance.
9.4.4 United States: AI Risk Management Framework (NIST RMF) and Sectoral Approach
Core Overview: The U.S. approach emphasizes fostering innovation through voluntary frameworks, industry best practices, and a sector-specific regulatory model rather than a single, comprehensive federal AI law. The White House has issued an Executive Order on AI, and various bills are under consideration at federal and state levels. A key guidance document is the National Institute of Standards and Technology (NIST) AI Risk Management Framework (AI RMF 1.0), released in January 2023, which is voluntary but highly influential.
NIST AI RMF Core Functions:
- GOVERN: Cultivate and implement a culture of risk management. This involves establishing policies, processes, responsibilities, and organizational schemes to anticipate, identify, and manage AI risks. Effective governance is a cross-cutting function. This aligns with findings that CEO oversight of AI governance correlates with higher bottom-line impact, though only 28% of organizations using AI report their CEO is responsible for overseeing AI governance.
- MAP: Establish the context to frame risks related to an AI system. This involves understanding the system's capabilities, intended uses, potential beneficiaries and impacted individuals, data sources, and limitations.
- MEASURE: Employ quantitative and qualitative tools and methodologies to analyze, assess, benchmark, and track AI risks and their impacts. This function is critical, especially as many organizations struggle with monitoring; for instance, 71% are not able to continuously monitor their GenAI systems.
- MANAGE: Consistently allocate risk resources to treat identified AI risks based on the outcomes from the Map, Measure, and Govern functions. This involves prioritizing and acting on risks.
Trustworthy AI Characteristics (NIST): The RMF aims to help organizations design, develop, deploy, and use AI systems that are valid and reliable, safe, secure and resilient, accountable and transparent, explainable and interpretable, privacy-enhanced, and fair with their harmful biases managed.
Business Implications: The NIST AI RMF encourages organizations to proactively identify, assess, and manage risks associated with AI. While voluntary, its adoption can demonstrate due diligence, enhance trustworthiness, and prepare businesses for potential future sectoral regulations or evolving legal standards. Businesses must also monitor emerging state-level legislation (e.g., in California) which may impose more specific requirements. The challenge of monitoring systems effectively remains a significant hurdle for many.
11.5 Legal Implications and Compliance Requirements
The integration of Generative AI into business operations introduces a complex array of legal challenges and compliance obligations. These extend beyond ethical guidelines and regulatory frameworks, touching upon established legal principles in areas like intellectual property, data privacy, and liability. Navigating this landscape requires careful legal counsel and robust internal governance.
9.5.1 Intellectual Property Infringement
One of the most contentious legal battlegrounds for GenAI revolves around intellectual property rights.
Training Data: GenAI models are often trained on vast datasets scraped from the internet, which may include copyrighted text, images, source code, and audio-visual works. Using such materials without explicit licenses from rights holders poses significant risks of copyright infringement. Several high-profile lawsuits have been filed by authors, artists, and media companies against AI developers, alleging unauthorized use of their works for training models. Defenses like "fair use" in the U.S. or text and data mining exceptions in the EU are being tested in this new context, and their applicability is often uncertain.
Generated Output: The output generated by GenAI can also infringe on existing copyrights if it is substantially similar to protected works. Some cases exemplify this risk where AI-generated imagery allegedly mimicked iconic film images. Furthermore, the question of who owns the copyright to AI-generated works is complex. Current U.S. Copyright Office guidance suggests that works generated solely by AI without sufficient human authorship are not eligible for copyright protection. The EU also generally requires human intellect in the creation process for copyright eligibility.
Liability: Determining who is liable for IP infringement involving GenAI—the developer of the AI tool, the business deploying the tool, or the end-user prompting the output—is an evolving legal question, often dependent on specific contractual terms and the degree of control each party has.
9.5.2 Data Protection and Privacy Violations
GenAI's reliance on data makes data protection and privacy a critical legal concern, especially as 76% of organizations express concern about data privacy with GenAI.
Personal Data in Training/Input: Using personal data to train GenAI models or processing personal data through AI applications without a valid legal basis (e.g., consent, legitimate interest, contractual necessity) can lead to violations of data protection laws like the GDPR in Europe, the CCPA in California, or sector-specific laws like HIPAA in healthcare. The inadvertent generation of profiles resembling real individuals from sensitive training data also poses significant privacy risks.
Confidentiality Breaches: Inputting proprietary business information, trade secrets, or client confidential data into third-party GenAI tools can lead to breaches if the data is not handled securely or if the AI provider uses such inputs to further train their models. Contractual terms regarding data confidentiality are paramount.
Transparency and User Rights: Organizations using GenAI to process personal data have obligations to inform individuals about this processing and to facilitate their data subject rights (e.g., access, rectification, erasure).
9.5.3 Liability for AI-Generated Content and Actions
Businesses can face legal liability for harm caused by the outputs or actions of GenAI systems they develop or deploy.
Errors and Inaccuracies ("Hallucinations"): If a business relies on or disseminates false or inaccurate information generated by AI, it may be liable for resulting damages. Examples include a company being held liable for misinformation provided by its chatbot or an attorney facing sanctions for submitting a legal brief with fake case citations generated by a chatbot. It has been found that only 27% of respondents reported their organizations are mitigating accuracy risks for all relevant GenAI use cases.
Defamation and Harmful Content: If a GenAI system produces defamatory statements, hate speech, or other illegal content, the deploying organization could face legal action.
Discrimination: As seen in some settlements, if AI systems lead to discriminatory outcomes in areas like hiring, lending, or housing, businesses can face significant legal and financial repercussions.
9.5.4 Contractual Risks and Considerations
When licensing or procuring GenAI solutions, businesses must carefully scrutinize contractual terms to mitigate legal risks.
Terms of Service with AI Providers: Key clauses to examine include those pertaining to data ownership (input and output), IP rights for generated content, limitations of liability, indemnification for third-party claims (e.g., IP infringement, privacy breaches), and data usage policies (e.g., whether provider can use customer data to improve models). These considerations are important for business continuity and assessing if relevant insurance is available.
Warranties and Disclaimers: Many GenAI providers offer their tools "as-is" with limited or no warranties regarding the accuracy, reliability, or non-infringement of generated output. Businesses must understand these limitations and the potential risks they assume.
9.5.5 Compliance Strategies and Governance Frameworks for Businesses
Addressing these legal implications requires proactive compliance strategies and robust governance.
- Developing AI Governance: Establish clear internal policies, ethical guidelines, risk assessment procedures, and oversight mechanisms for GenAI development and use. The fact that 95% of organizations lack a comprehensive governance framework for GenAI highlights a critical gap. CEO oversight is also correlated with higher bottom-line impact from AI.
- Due Diligence: Thoroughly vet AI tools and vendors for their security practices, privacy policies, approaches to bias mitigation, and IP compliance.
- Data Management and Quality: Implement strong data governance practices. This includes addressing unstructured data issues, as 92% of organizations report these impacting their GenAI initiatives. Common approaches include fine-tuning models on existing data (57%) and adding new data management/quality solutions (48%). Focus on ensuring data provenance and quality, and remediating issues like duplicate files (66%), out-of-date information (53%), and conflicting versions (47%).
- Monitoring and Auditing: Implement systems to continuously monitor GenAI performance for accuracy, bias, privacy preservation, and security. Currently, seven in ten (71%) organizations are not able to continuously monitor their GenAI systems, and only 5% have a reliable system to measure bias and privacy risk in LLMs.
- Training and Awareness: Educate employees on a company's AI policies, responsible AI use, potential risks (e.g., inputting confidential data), and how to identify and report issues.
- Legal Counsel and Regulatory Tracking: Engage legal experts specializing in AI and technology law to navigate complex issues and stay abreast of the rapidly evolving regulatory landscape.
11.6 Conclusion
Generative AI stands as a paradigm-shifting technology, offering unprecedented opportunities for innovation and efficiency across the business spectrum. However, its transformative power is intrinsically linked to a complex array of ethical dilemmas, potential workforce and societal disruptions, a nascent and diverse global regulatory environment, and significant legal and compliance hurdles. As this chapter has detailed, navigating this landscape is not merely an operational challenge but a strategic imperative for any organization looking to leverage GenAI responsibly and sustainably.
The core challenges—ranging from algorithmic bias, data privacy vulnerabilities, and intellectual property entanglements to the risks of misinformation, job displacement, and economic inequality—are substantial. The current state of organizational preparedness, as highlighted by data indicating widespread lack of comprehensive governance frameworks and deficiencies in monitoring capabilities, underscores the urgency for businesses to act decisively.
The imperative for proactive and adaptive governance cannot be overstated. Managing the risks associated with GenAI is an ongoing commitment, not a one-time project, especially given the rapid pace of technological evolution and regulatory change. This demands the establishment of robust internal governance structures, continuous monitoring and auditing of AI systems (addressing the current 71% gap in monitoring capabilities), and the cultivation of a strong culture of ethical awareness and responsibility, ideally driven from the highest levels of leadership. While many organizations (55%) plan to address underlying data issues in the next 12-24 months, broader governance requires sustained focus.
For businesses, the path forward lies in embracing a balanced approach: one that actively fosters innovation while embedding ethical principles, ensuring regulatory compliance, and building stakeholder trust from the outset. This is not just about risk mitigation; responsible AI adoption can be a significant strategic differentiator, enhancing brand reputation and fostering long-term value creation. As the GenAI landscape continues to mature, collaboration between industry leaders, policymakers, academics, and civil society will be crucial in shaping a future where this powerful technology serves to benefit humanity as a whole, promoting shared prosperity and upholding fundamental rights.
Key Terminologies
This glossary provides clear, business-focused definitions of essential Generative AI concepts. Whether you're a manager, strategist, or practitioner, these terms will help you navigate the GenAI landscape with confidence.
1. Model Parameters
Parameters are the adjustable "knobs" inside an AI model — the numerical values it learns during training. A large model like GPT-5 can have trillions of parameters, each capturing patterns from the training data. Together, they determine how the model predicts, generates, and reasons. More parameters usually mean more capability but also higher computational cost.
2. Fine-Tuning
Fine-tuning means taking a general AI model and retraining it on smaller, specialized datasets. It teaches the model new vocabulary, tone, or domain knowledge — for example, adapting a general chatbot into a legal assistant or marketing strategist. It's cheaper and faster than training a model from scratch and helps align the AI with company-specific goals or style.
3. Temperature
Temperature controls how creative or predictable a model's responses are:
- Low temperature (0.1–0.3): Deterministic and factual. Ideal for reports, code, and analysis.
- Medium (0.4–0.7): Balanced. Good for general writing and reasoning.
- High (0.8–1.0): Creative, diverse, sometimes unpredictable. Useful for brainstorming or storytelling.
In short, temperature adjusts the randomness of the model's next-word choices.
4. Top-K Sampling
Top-K limits how many possible next words (tokens) the model considers. For example, with K = 50, the model only looks at the 50 most likely next words and picks one according to their probabilities. This helps control randomness and ensures coherent, focused output — often used together with Top-P (nucleus sampling).
5. Retrieval-Augmented Generation (RAG)
RAG connects an AI model to external information sources (like documents or databases). The model first retrieves relevant facts (like a "librarian") and then generates a response using that material (like an "author"). It keeps AI answers accurate, up-to-date, and grounded in real data — essential for enterprise use cases.
6. Context Engineering
Context engineering is about designing the environment the AI uses to think and respond. It includes what background information, examples, or roles you give the model. Good context engineering turns a general AI into a domain-aware assistant — for instance, providing company tone guidelines or past customer interactions as context before generation.
7. The Five A's of Applied GenAI
A framework to understand how GenAI transforms work at different levels:
| Stage | Focus | Example |
|---|---|---|
| Access | Using foundation models (GPT, Claude, Gemini) | Using ChatGPT for idea drafts |
| Assistants | Domain-specific chatbots | Customer-service AI |
| Application | Task-specific tools | AI slide generator, writing assistant |
| Automation | Workflow integration | n8n, Zapier AI, Make.com |
| Agents | Autonomous systems | AI agent scheduling tasks independently |
It shows how organizations move from using GenAI casually to embedding it deeply into operations.
8. The EDGE Framework
A strategic model for capturing GenAI's value:
| Dimension | Meaning | Goal |
|---|---|---|
| E – Efficiency | Streamline and automate processes | Cost and time savings |
| D – Decisions | Use AI insights for strategy | Smarter, data-driven choices |
| G – Growth | Innovate with new products and services | Revenue and market expansion |
| E – Empowerment | Enhance human creativity and capability | Happier, upskilled workforce |
EDGE helps executives balance productivity with innovation and human development.
9. Prompt Engineering
The craft of designing inputs (prompts) to guide AI models toward better results. Good prompts are clear, specific, and structured. They may include roles ("You are a marketing analyst"), examples, or constraints ("Answer in two bullet points"). Advanced methods include:
- Chain of Thought (CoT): Ask the model to reason step-by-step.
- Tree of Thought (ToT): Explore multiple reasoning paths before deciding.
- Self-Consistency: Generate several answers and choose the best.
10. Tokenization
Before a model processes text, it breaks it into tokens — small units (words, subwords, or symbols). For example, "marketing" might become [mark, et, ing]. The model predicts one token at a time. Token count affects cost and length limits: longer prompts = more tokens = higher usage cost.
11. Scaling Laws
Scaling laws describe how AI performance improves as you increase model size, data, and compute power — usually in predictable ways. The rule of thumb: bigger models trained on more data with more compute generally perform better, but returns diminish after a point.
12. Agents
AI agents can understand goals, plan tasks, and execute them autonomously using tools or APIs. They go beyond chatbots — for example, an agent could research competitors, write a summary, and email it automatically. They're key to the future of fully automated business workflows.
13. API (Application Programming Interface)
An API is a bridge that lets software systems talk to each other. For Generative AI, APIs allow apps or platforms to send a prompt to a model (like GPT-5) and receive the output automatically. Companies use APIs to integrate AI into existing products — for example, generating summaries inside Slack, or automating customer replies in a CRM. APIs make AI scalable and programmable rather than manually chat-based.
14. Playground
A playground is a sandbox environment where users can experiment with AI models safely. Platforms like OpenAI Playground, Google AI Studio, and Hugging Face Spaces let users test prompts, adjust parameters (like temperature and top-p), and preview outputs before integrating them into real workflows.
15. Zero-Shot, One-Shot, and Few-Shot Learning
These terms describe how much prior example input a model receives for a task:
- Zero-Shot: The model is asked to perform a task with no examples ("Summarize this article").
- One-Shot: You show one example of what you want.
- Few-Shot: You give multiple examples to teach the model the right format or tone.
This flexibility makes large language models adaptable to almost any task with minimal training.
16. Chain of Thought (CoT)
CoT prompting asks the model to reason step-by-step rather than jump to a conclusion. For example: "Let's think step by step." This encourages the model to explain its logic, often improving accuracy and transparency — especially in math, analysis, and decision-making tasks.
17. Tree of Thought (ToT)
An evolution of Chain of Thought. Here, the AI explores multiple reasoning paths, compares them, and picks the best outcome — like branching options in a decision tree. Useful for open-ended questions, creativity, and problem solving (e.g., strategy planning or product design).
18. Self-Consistency
Instead of relying on one output, the model generates several answers to the same prompt, then chooses or averages the most consistent one. It's like getting second opinions from multiple experts. This improves reliability and reduces randomness in complex reasoning tasks.
19. ReAct (Reason + Act)
ReAct combines reasoning with actions. The model thinks, then acts — such as searching the web, running code, or calling another tool — and then continues reasoning with the new data. This approach is the backbone of AI agents that can autonomously complete workflows.
20. Governance Framework (for GenAI)
AI governance refers to the rules, structures, and oversight that ensure safe, fair, and legal AI use. A good framework covers:
- Data privacy and bias management
- Model transparency and accountability
- Security and monitoring systems
- Clear ownership and escalation procedures
Without governance, even powerful AI systems can become risky or non-compliant.
21. Synthetic Data
Synthetic data is artificially generated rather than collected from real users. It mimics real-world patterns while protecting privacy and allowing controlled experimentation. For example, a retail firm might create synthetic customer reviews to train sentiment-analysis models without exposing real identities. It's vital for research, testing, and model robustness.
22. Hallucination
A hallucination occurs when an AI model produces confident but false or fabricated information. It can happen due to incomplete training data or ambiguous prompts. Mitigation methods include RAG, context engineering, and human verification loops. Hallucination control is one of the key challenges for deploying GenAI in business.
23. Scaling Up vs. Scaling Out
Scaling up means using bigger models or hardware (more parameters, GPUs, or memory).
Scaling out means distributing workloads across multiple smaller systems or specialized models.
Businesses often start with scaling out for flexibility and cost control before moving to larger-scale infrastructure.
24. Token Limit / Context Window
Every model has a maximum "context window" — the total number of tokens (words and symbols) it can process at once. For example, GPT-5 might handle 128k tokens (roughly a 200-page book). Longer context windows allow richer reasoning, but also cost more and take longer to compute.
25. Multimodality
A multimodal model can process more than one type of data — text, image, audio, video, or code — and combine them in output. For example, describing an image, generating a video from text, or analyzing both visuals and language together. This is central to next-generation AI (like GPT-5 or Gemini 2.5).
26. Workflow Automation
The use of AI to connect apps and automate repetitive tasks. Platforms like Zapier, n8n, and Make.com allow users to trigger AI actions (generate, summarize, translate) automatically. It's where GenAI moves from idea generation to continuous business process execution.
27. Prompt Chaining
Breaking a complex task into a series of smaller prompts where each step feeds the next. Example:
- Summarize a long report.
- Extract key insights.
- Turn insights into slides.
Each output becomes the next input — ideal for automation pipelines.
28. Embeddings
Embeddings are numerical representations of text that capture meaning and similarity. They allow the AI to understand relationships between concepts (e.g., "Paris" and "France" are close in vector space). Embeddings are key to search, recommendation, and RAG systems.
29. Latent Space
Latent space is the model's internal map of concepts — a multidimensional representation of ideas learned during training. In this space, similar things are closer together (e.g., "luxury" and "elegant"). When AI generates text or images, it navigates through this space to produce coherent results.
30. Diffusion Model
A type of generative model that starts with random noise and gradually refines it into a meaningful image or sound. Used in image and video generation tools (like DALL·E, Midjourney, and Stable Diffusion). It's the opposite of "adding noise" — it learns how to remove noise step by step to create clarity.
31. Explainability (XAI)
Explainable AI helps users understand why a model made a decision or produced an answer. It's crucial for trust, compliance, and ethical deployment — especially in finance, healthcare, and HR. Techniques include attention visualization, example tracing, and natural-language justifications.
32. Model Alignment
Model alignment ensures AI behaves according to human values, safety, and intent. It's achieved through training methods like reinforcement learning with human feedback (RLHF) and ongoing supervision. Alignment aims to make AI helpful, harmless, and honest.
33. Data Moat
A data moat is a competitive advantage built from proprietary data that others can't easily copy. In GenAI, the more unique and high-quality data you have for fine-tuning or RAG, the stronger your moat — because your AI becomes more specialized and accurate.
34. Human-in-the-Loop (HITL)
A design where humans remain part of the AI process — reviewing, correcting, or approving outputs. HITL ensures quality, reduces risk, and helps models learn from human feedback. It's essential for ethical and reliable enterprise AI.
35. GenAI Operating Model
A GenAI operating model defines how an organization manages AI across functions — covering structure, workflows, ownership, and governance. It specifies who builds, who monitors, and who approves AI use cases, ensuring consistency and accountability across departments.
Acknowledgements
Acknowledgements content will go here.